Skip to content
…
…
…
…
We’re forming a new industry body to promote the safe and responsible development of frontier AI systems: advancing AI safety research, identifying best practices and standards, and facilitating information sharing among policymakers and industry.…
…
We need scientific and technical breakthroughs to steer and control AI systems much smarter than us. To solve this problem within four years, we’re starting a new team, co-led by Ilya Sutskever and Jan Leike, and dedicating 20% of the…
Now is a good time to start thinking about the governance of superintelligence—future AI systems dramatically more capable than even AGI.…
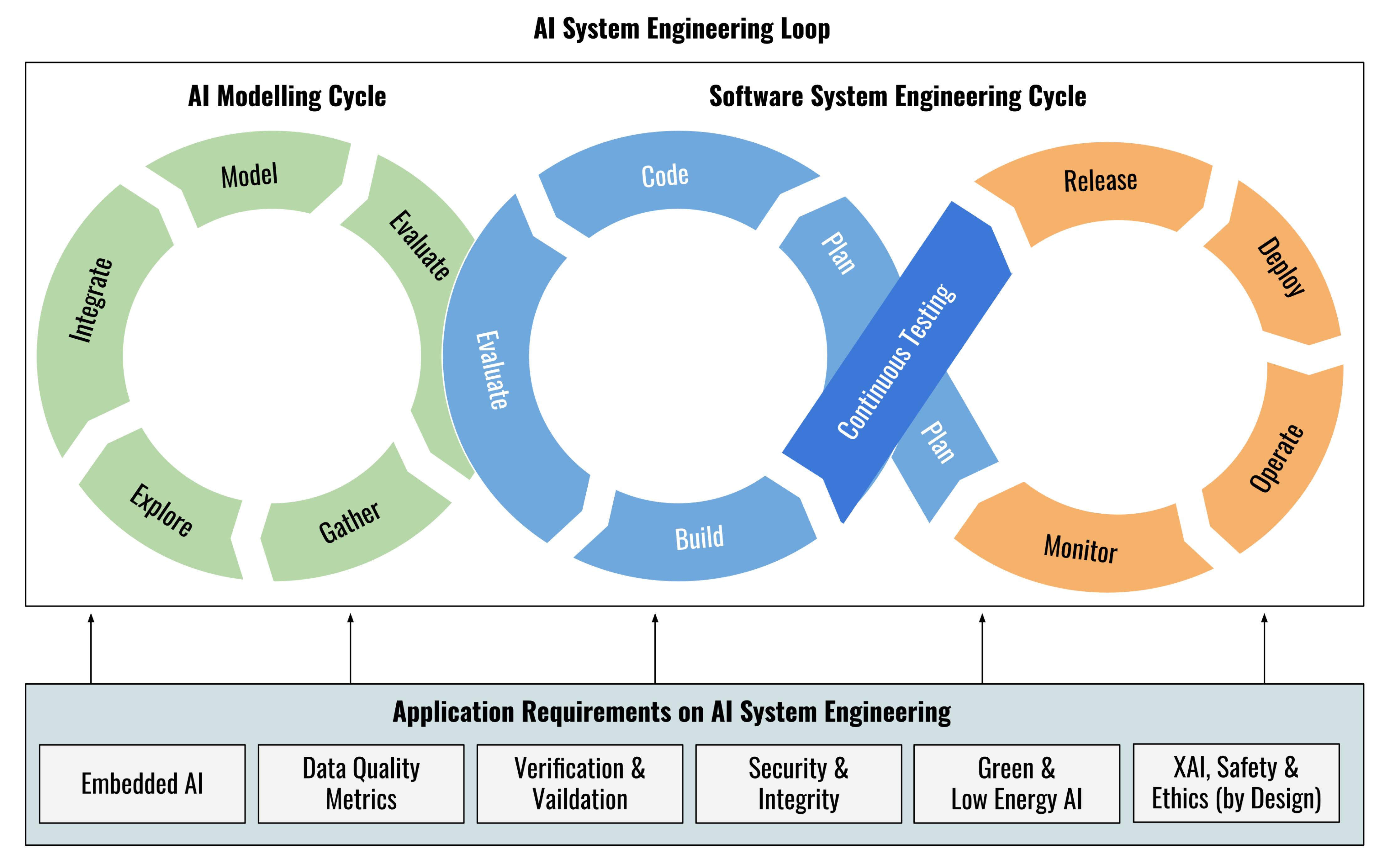
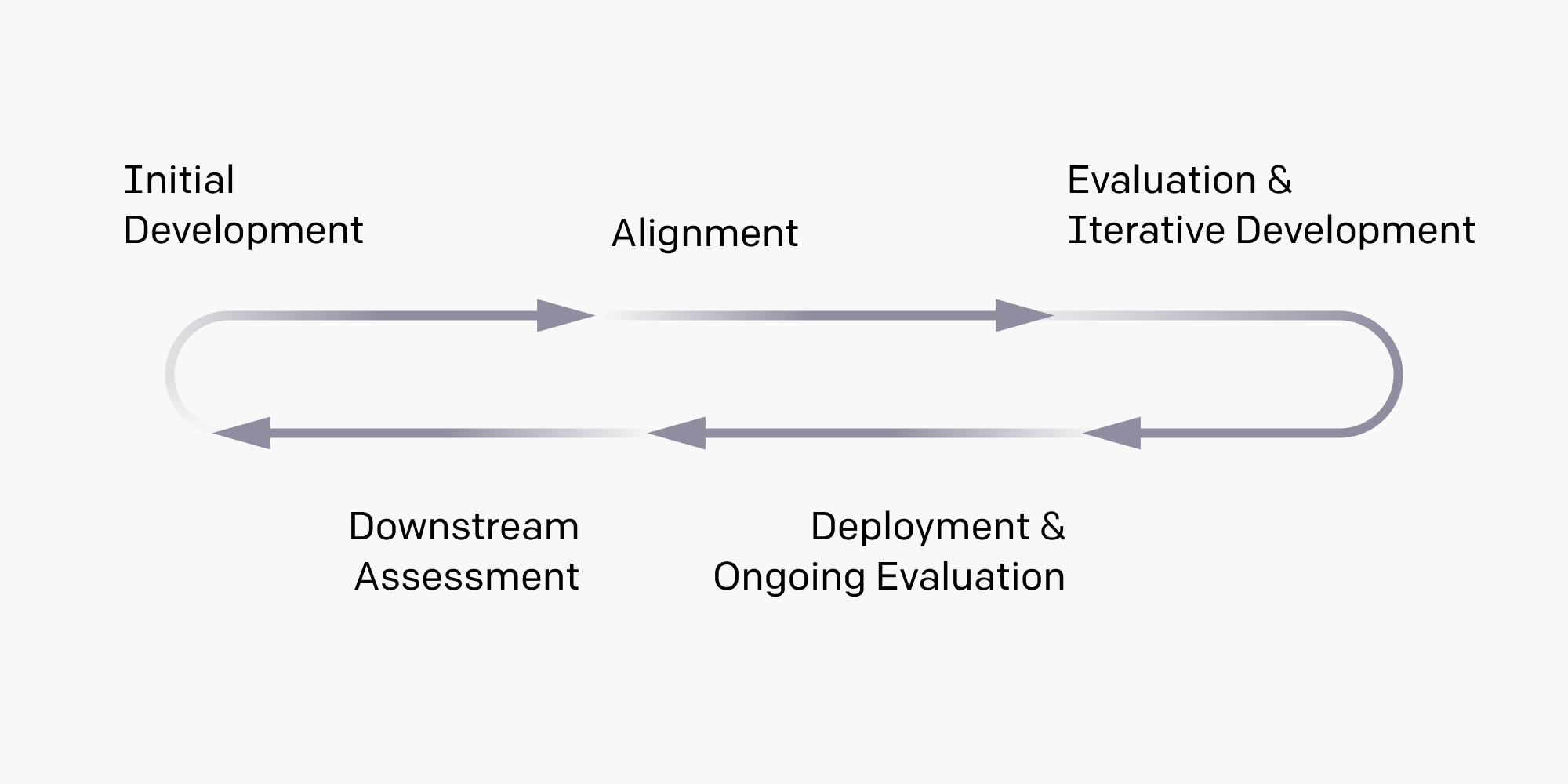
Ensuring that AI systems are built, deployed, and used safely is critical to our mission.…
Our mission is to ensure that artificial general intelligence—AI systems that are generally smarter than humans—benefits all of humanity.…
We’re clarifying how ChatGPT’s behavior is shaped and our plans for improving that behavior, allowing more user customization, and getting more public input into our decision-making in these areas.…
OpenAI researchers collaborated with Georgetown University’s Center for Security and Emerging Technology and the Stanford Internet Observatory to investigate how large language models might be misused for disinformation purposes. The collaboration included an October 2021 workshop bringing together 30 disinformation…
We are improving our AI systems’ ability to learn from human feedback and to assist humans at evaluating AI. Our goal is to build a sufficiently aligned AI system that can help us solve all other alignment problems.…
…
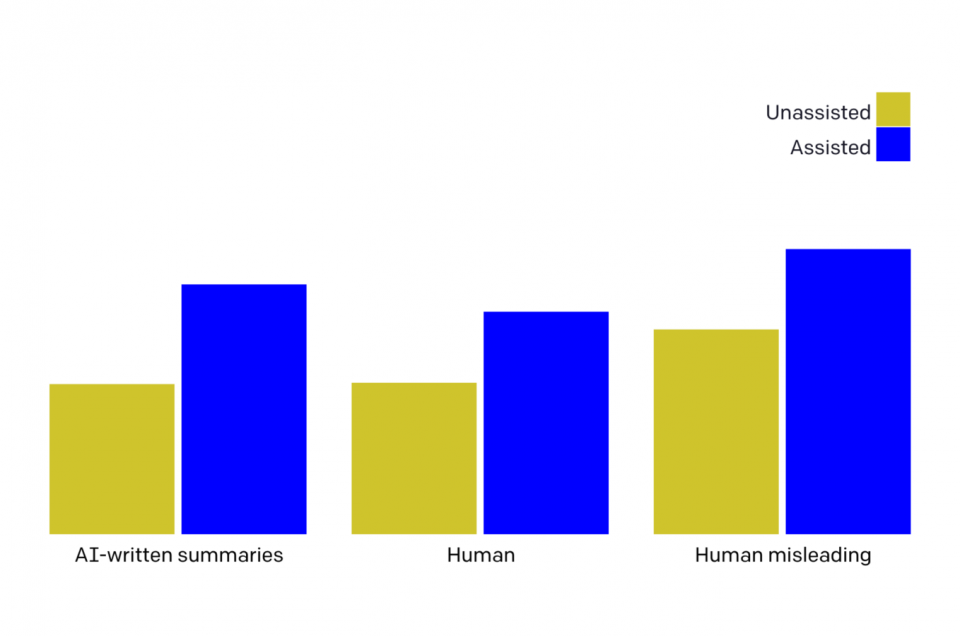
We trained “critique-writing” models to describe flaws in summaries. Human evaluators find flaws in summaries much more often when shown our model’s critiques. Larger models are better at self-critiquing, with scale improving critique-writing more than summary-writing. This shows promise for…
Cohere, OpenAI, and AI21 Labs have developed a preliminary set of best practices applicable to any organization developing or deploying large language models.…
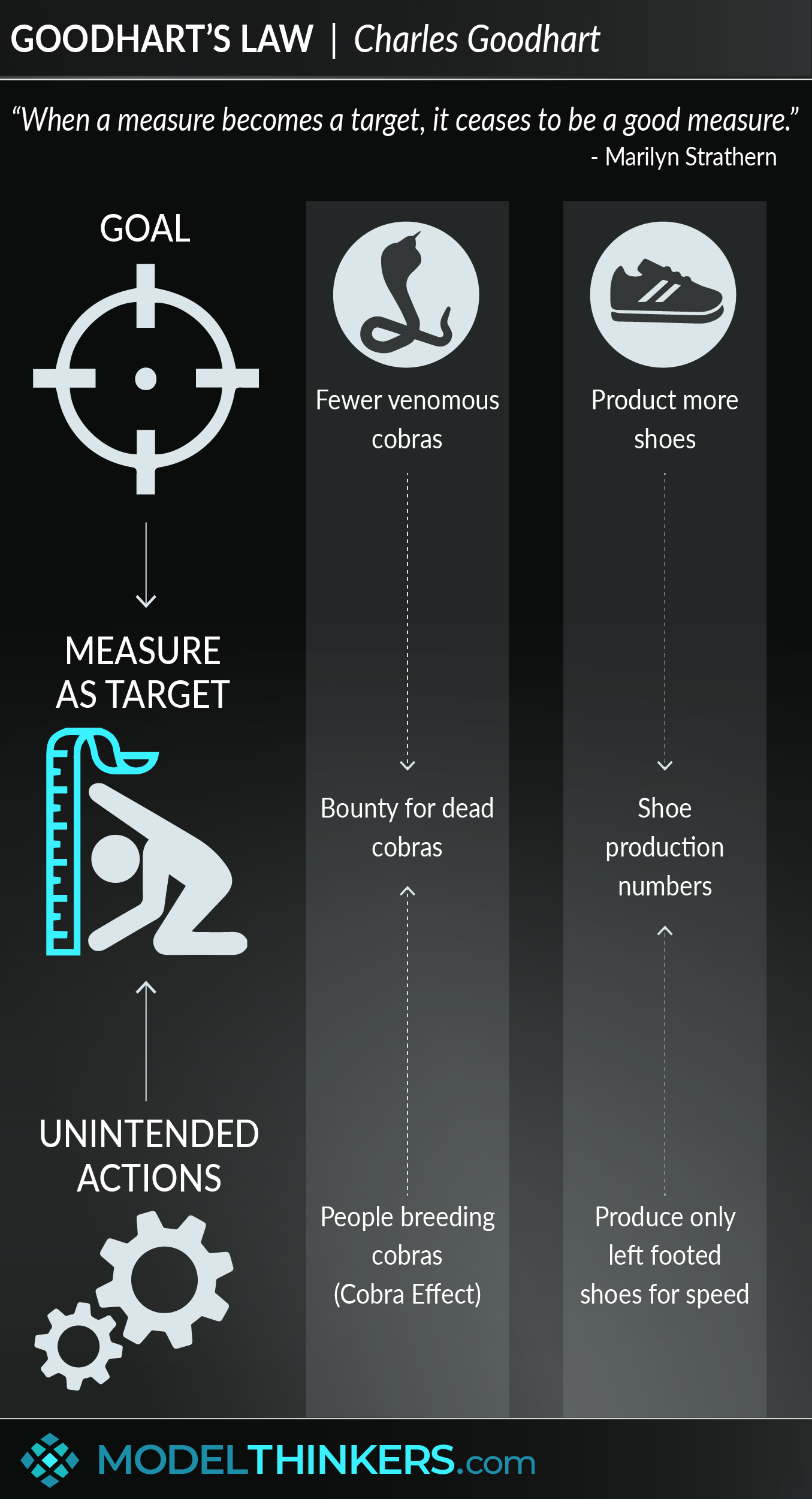
Goodhart’s law famously says: “When a measure becomes a target, it ceases to be a good measure.” Although originally from economics, it’s something we have to grapple with at OpenAI when figuring out how to optimize objectives that are difficult…
We describe our latest thinking in the hope of helping other AI developers address safety and misuse of deployed models.…
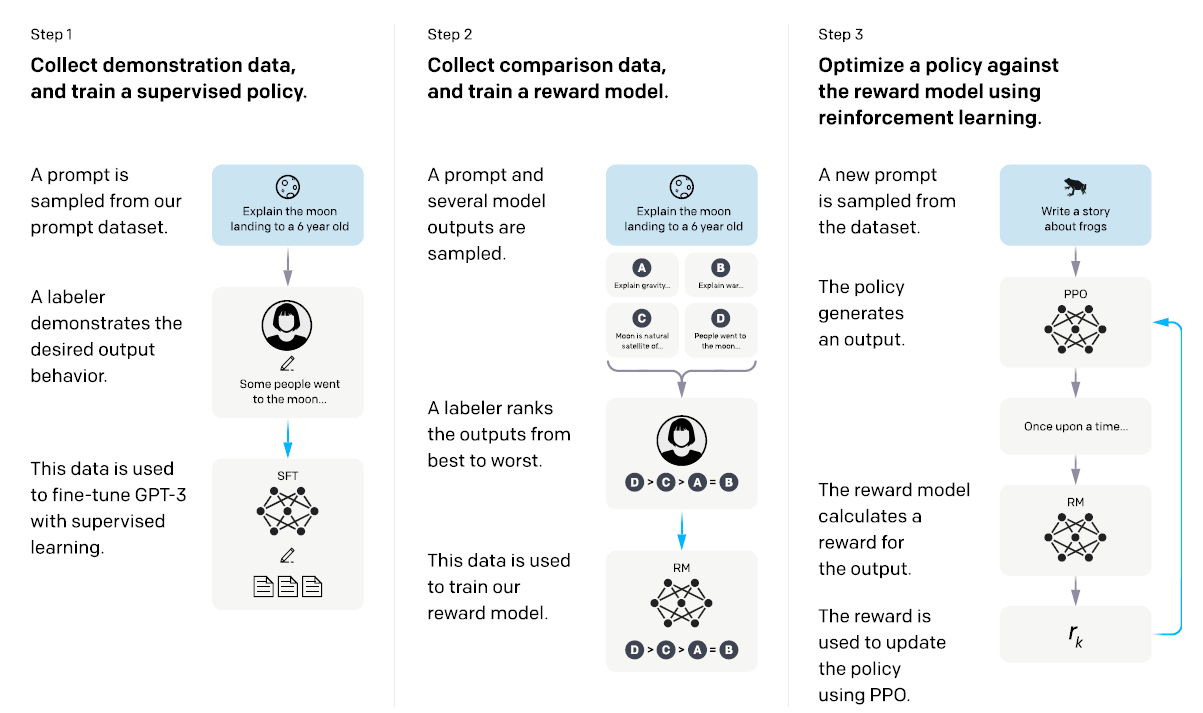
We’ve trained language models that are much better at following user intentions than GPT-3 while also making them more truthful and less toxic, using techniques developed through our alignment research. These InstructGPT models, which are trained with humans in the…
文 » A
Scroll Up
×
![]()