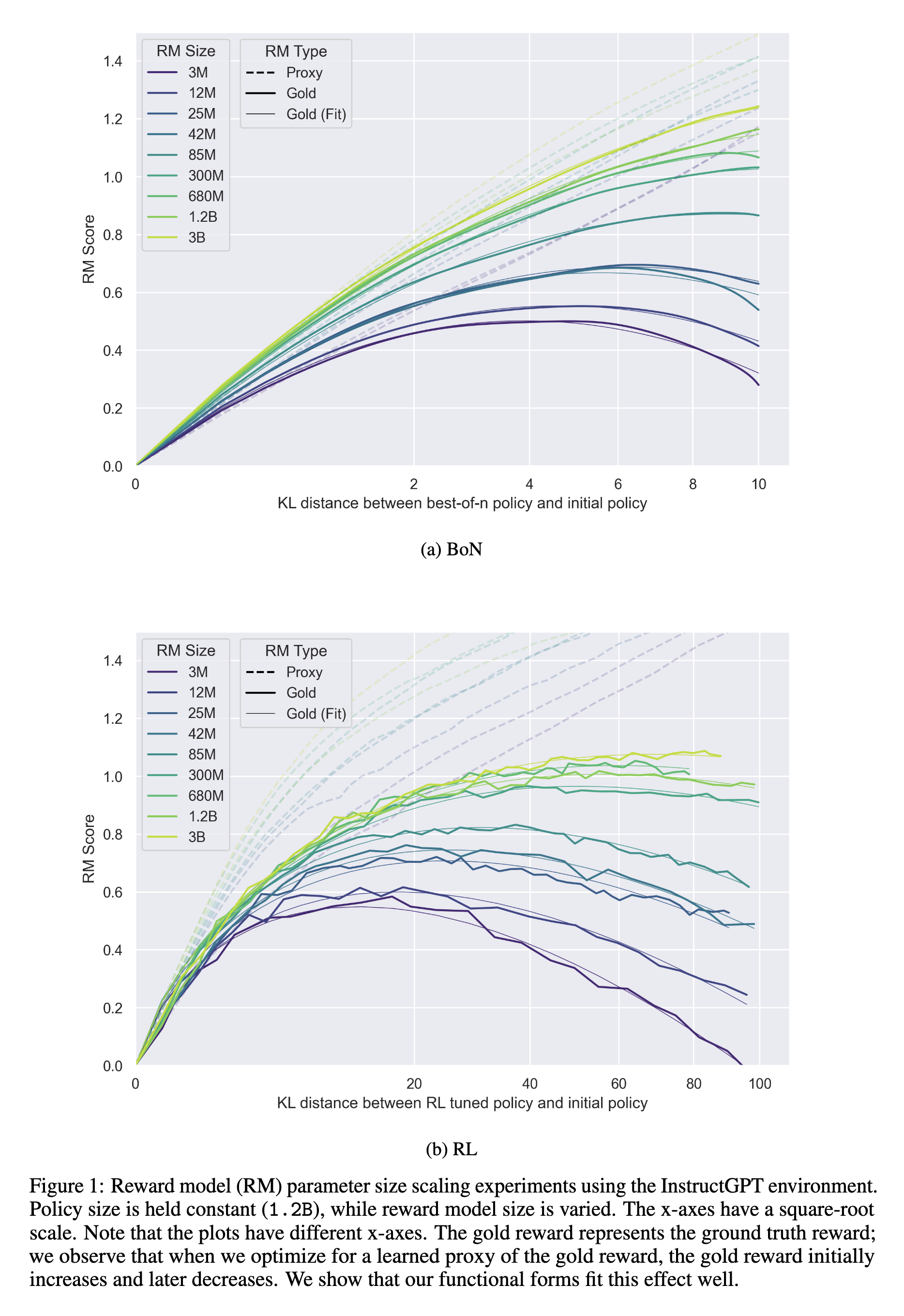
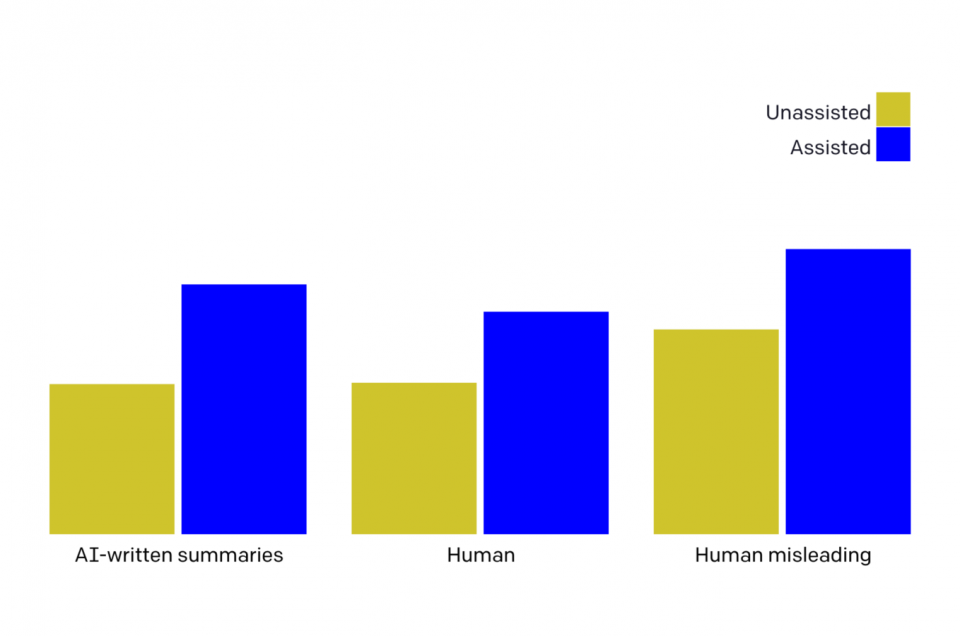
AI-written critiques help humans notice flaws We trained “critique-writing” models to describe flaws in summaries. Human evaluators find flaws in summaries much more often when shown our model’s critiques. Larger models are better at self-critiquing, with scale improving critique-writing more than summary-writing. This shows promise for…
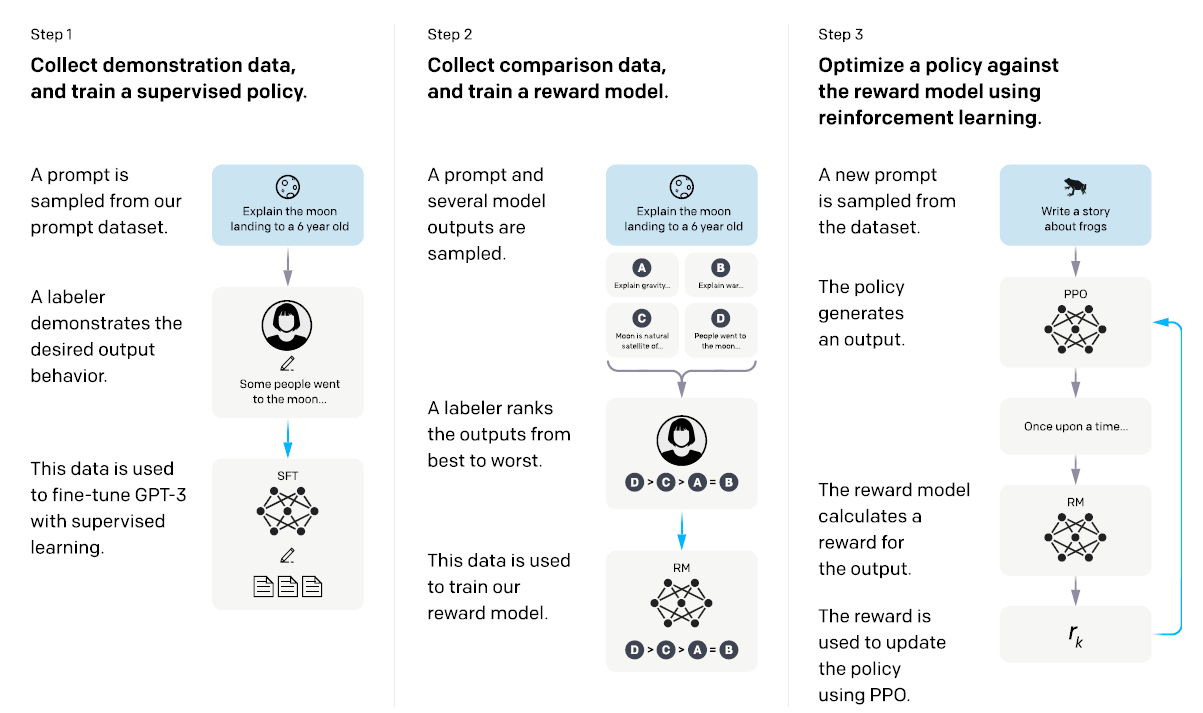
Aligning language models to follow instructions We’ve trained language models that are much better at following user intentions than GPT-3 while also making them more truthful and less toxic, using techniques developed through our alignment research. These InstructGPT models, which are trained with humans in the…