
Amazon Polly is a service that turns text into lifelike speech. It enables the development of a whole class of applications that can convert text into speech in multiple languages.
This service can be used by chatbots, audio books, and other text-to-speech applications in conjunction with other AWS AI or machine learning (ML) services. For example, Amazon Lex and Amazon Polly can be combined to create a chatbot that engages in a two-way conversation with a user and performs certain tasks based on the user’s commands. Amazon Transcribe, Amazon Translate, and Amazon Polly can be combined to transcribe speech to text in the source language, translate it to a different language, and speak it.
In this post, we present an interesting approach for highlighting text as it’s being spoken using Amazon Polly. This solution can be used in many text-to-speech applications to do the following:
- Add visual capabilities to audio in books, websites, and blogs
- Increase comprehension when customers are trying to understand the text rapidly as it’s being spoken
Our solution gives the client (the browser, in this example), the ability to know what text (word or sentence) is being spoken by Amazon Polly at any instant. This enables the client to dynamically highlight the text as it’s being spoken. Such a capability is useful for providing visual aid to speech for the use cases mentioned previously.
Our solution can be extended to perform additional tasks besides highlighting text. For example, the browser can show images, play music, or perform other animations on the front end as the text is being spoken. This capability is useful for creating dynamic audio books, educational content, and richer text-to-speech applications.
Solution overview
At its core, the solution uses Amazon Polly to convert a string of text into speech. The text can be input from the browser or through an API call to the endpoint exposed by our solution. The speech generated by Amazon Polly is stored as an audio file (MP3 format) in an Amazon Simple Storage Service (Amazon S3) bucket.
However, using the audio file alone, the browser can’t find what parts of the text are being spoken at any instant because we don’t have granular information on when each word is spoken.
Amazon Polly provides a way to obtain this using speech marks. Speech marks are stored in a text file that shows the time (measured in milliseconds from start of the audio) when each word or sentence is spoken.
Amazon Polly returns speech mark objects in a line-delimited JSON stream. A speech mark object contains the following fields:
- Time – The timestamp in milliseconds from the beginning of the corresponding audio stream
- Type – The type of speech mark (sentence, word, viseme, or SSML)
- Start – The offset in bytes (not characters) of the start of the object in the input text (not including viseme marks)
- End – The offset in bytes (not characters) of the object’s end in the input text (not including viseme marks)
- Value – This varies depending on the type of speech mark:
- SSML – <mark> SSML tag
- Viseme – The viseme name
- Word or sentence – A substring of the input text as delimited by the start and end fields
For example, the sentence “Mary had a little lamb” can give you the following speech marks file if you use SpeechMarkTypes = [“word”, “sentence”] in the API call to obtain the speech marks:
The word “had” (at the end of line 3) begins 373 milliseconds after the audio stream begins, starts at byte 5, and ends at byte 8 of the input text.
Architecture overview
The architecture of our solution is presented in the following diagram.
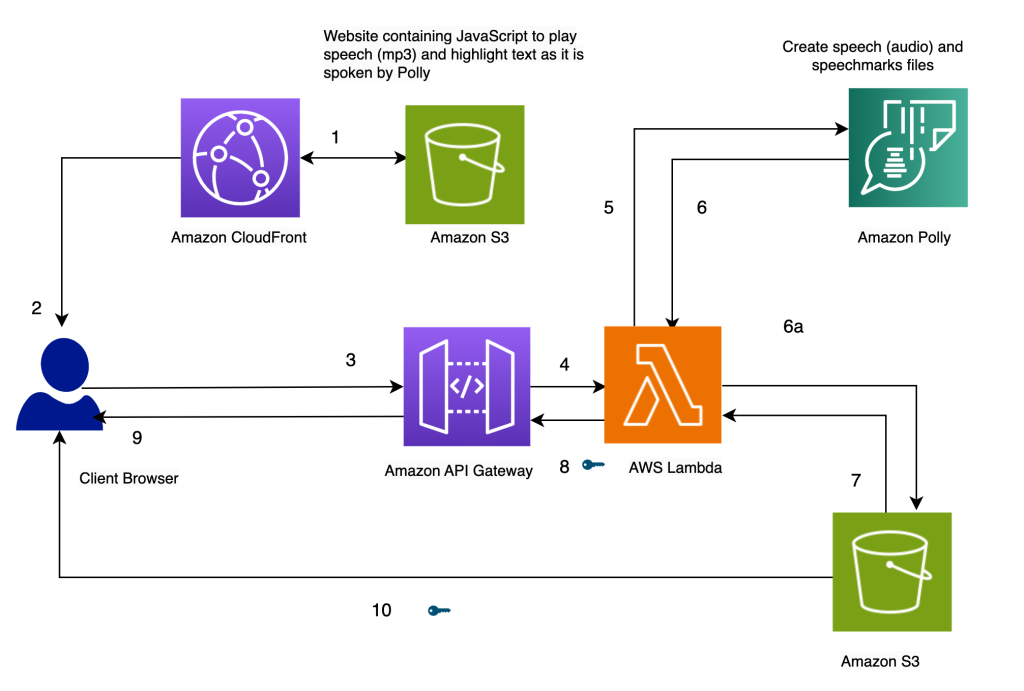
Highlight Text as it’s spoken, using Amazon Polly
Our website for the solution is stored on Amazon S3 as static files (JavaScript, HTML), which are hosted in Amazon CloudFront (1) and served to the end-user’s browser (2).
When the user enters text in the browser through a simple HTML form, it’s processed by JavaScript in the browser. This calls an API (3) through Amazon API Gateway, to invoke an AWS Lambda function (4). The Lambda function calls Amazon Polly (5) to generate speech (audio) and speech marks (JSON) files. Two calls are made to Amazon Polly to fetch the audio and speech marks files. The calls are made using JavaScript async functions. The output of these calls is the audio and speech marks files, which are stored in Amazon S3 (6a). To avoid multiple users overwriting each others’ files in the S3 bucket, the files are stored in a folder with a timestamp. This minimizes the chances of two users overwriting each others’ files in Amazon S3. For a production release, we can employ more robust approaches to segregate users’ files based on user ID or timestamp and other unique characteristics.
The Lambda function creates pre-signed URLs for the speech and speech marks files and returns them to the browser in the form of an array (7, 8, 9).
When the browser sends the text file to the API endpoint (3), it gets back two pre-signed URLs for the audio file and the speech marks file in one synchronous invocation (9). This is indicated by the key symbol next to the arrow.
A JavaScript function in the browser fetches the speech marks file and the audio from their URL handles (10). It sets up the audio player to play the audio. (The HTML audio tag is used for this purpose).
When the user clicks the play button, it parses the speech marks retrieved in the earlier step to create a series of timed events using timeouts. The events invoke a callback function, which is another JavaScript function used to highlight the spoken text in the browser. Simultaneously, the JavaScript function streams the audio file from its URL handle.
The result is that the events are run at the appropriate times to highlight the text as it’s spoken while the audio is being played. The use of JavaScript timeouts provides us the synchronization of the audio with the highlighted text.
Prerequisites
To run this solution, you need an AWS account with an AWS Identity and Access Management (IAM) user who has permission to use Amazon CloudFront, Amazon API Gateway, Amazon Polly, Amazon S3, AWS Lambda, and AWS Step Functions.
Use Lambda to generate speech and speech marks
The following code invokes the Amazon Polly synthesize_speech function two times to fetch the audio and speech marks file. They’re run as asynchronous functions and coordinated to return the result at the same time using promises.
On the JavaScript side, the text highlighting is done by highlighter(start, finish, word) and the timed events are set by setTimers():
Alternative approaches
Instead of the previous approach, you can consider a few alternatives:
- Create both the speech marks and audio files inside a Step Functions state machine. The state machine can invoke the parallel branch condition to invoke two different Lambda functions: one to generate speech and another to generate speech marks. The code for this can be found in the using-step-functions subfolder in the Github repo.
- Invoke Amazon Polly asynchronously to generate the audio and speech marks. This approach can be used if the text content is large or the user doesn’t need a real-time response. For more details about creating long audio files, refer to Creating Long Audio Files.
- Have Amazon Polly create the presigned URL directly using the
generate_presigned_urlcall on the Amazon Polly client in Boto3. If you go with this approach, Amazon Polly generates the audio and speech marks newly every time. In our current approach, we store these files in Amazon S3. Although these stored files aren’t accessible from the browser in our version of the code, you can modify the code to play previously generated audio files by fetching them from Amazon S3 (instead of regenerating the audio for the text again using Amazon Polly). We have more code examples for accessing Amazon Polly with Python in the AWS Code Library.
Create the solution
The entire solution is available from our Github repo. To create this solution in your account, follow the instructions in the README.md file. The solution includes an AWS CloudFormation template to provision your resources.
Cleanup
To clean up the resources created in this demo, perform the following steps:
- Delete the S3 buckets created to store the CloudFormation template (Bucket A), the source code (Bucket B) and the website (
pth-cf-text-highlighter-website-[Suffix]). - Delete the CloudFormation stack
pth-cf. - Delete the S3 bucket containing the speech files (
pth-speech-[Suffix]). This bucket was created by the CloudFormation template to store the audio and speech marks files generated by Amazon Polly.
Summary
In this post, we showed an example of a solution that can highlight text as it’s being spoken using Amazon Polly. It was developed using the Amazon Polly speech marks feature, which provides us markers for the place each word or sentence begins in an audio file.
The solution is available as a CloudFormation template. It can be deployed as is to any web application that performs text-to-speech conversion. This would be useful for adding visual capabilities to audio in books, avatars with lip-sync capabilities (using viseme speech marks), websites, and blogs, and for aiding people with hearing impairments.
It can be extended to perform additional tasks besides highlighting text. For example, the browser can show images, play music, and perform other animations on the front end while the text is being spoken. This capability can be useful for creating dynamic audio books, educational content, and richer text-to-speech applications.
We welcome you to try out this solution and learn more about the relevant AWS services from the following links. You can extend the functionality for your specific needs.
About the Author
 Varad G Varadarajan is a Trusted Advisor and Field CTO for Digital Native Businesses (DNB) customers at AWS. He helps them architect and build innovative solutions at scale using AWS products and services. Varad’s areas of interest are IT strategy consulting, architecture, and product management. Outside of work, Varad enjoys creative writing, watching movies with family and friends, and traveling.
Varad G Varadarajan is a Trusted Advisor and Field CTO for Digital Native Businesses (DNB) customers at AWS. He helps them architect and build innovative solutions at scale using AWS products and services. Varad’s areas of interest are IT strategy consulting, architecture, and product management. Outside of work, Varad enjoys creative writing, watching movies with family and friends, and traveling.