
In this two-part series, we demonstrate how to label and train models for 3D object detection tasks. In part 1, we discuss the dataset we’re using, as well as any preprocessing steps, to understand and label data. In part 2, we walk through how to train a model on your dataset and deploy it to production.
LiDAR (light detection and ranging) is a method for determining ranges by targeting an object or surface with a laser and measuring the time for the reflected light to return to the receiver. Autonomous vehicle companies typically use LiDAR sensors to generate a 3D understanding of the environment around their vehicles.
As LiDAR sensors become more accessible and cost-effective, customers are increasingly using point cloud data in new spaces like robotics, signal mapping, and augmented reality. Some new mobile devices even include LiDAR sensors. The growing availability of LiDAR sensors has increased interest in point cloud data for machine learning (ML) tasks, like 3D object detection and tracking, 3D segmentation, 3D object synthesis and reconstruction, and using 3D data to validate 2D depth estimation.
In this series, we show you how to train an object detection model that runs on point cloud data to predict the location of vehicles in a 3D scene. This post, we focus specifically on labeling LiDAR data. Standard LiDAR sensor output is a sequence of 3D point cloud frames, with a typical capture rate of 10 frames per second. To label this sensor output you need a labeling tool that can handle 3D data. Amazon SageMaker Ground Truth makes it easy to label objects in a single 3D frame or across a sequence of 3D point cloud frames for building ML training datasets. Ground Truth also supports sensor fusion of camera and LiDAR data with up to eight video camera inputs.
Data is essential to any ML project. 3D data in particular can be difficult to source, visualize, and label. We use the A2D2 dataset in this post and walk you through the steps to visualize and label it.
A2D2 contains 40,000 frames with semantic segmentation and point cloud labels, including 12,499 frames with 3D bounding box labels. Since we are focusing on object detection, we’re interested in the 12,499 frames with 3D bounding box labels. These annotations include 14 classes relevant to driving like car, pedestrian, truck, bus, etc.
The following table shows the complete class list:
| Index | Class list |
| 1 | animal |
| 2 | bicycle |
| 3 | bus |
| 4 | car |
| 5 | caravan transporter |
| 6 | cyclist |
| 7 | emergency vehicle |
| 8 | motor biker |
| 9 | motorcycle |
| 10 | pedestrian |
| 11 | trailer |
| 12 | truck |
| 13 | utility vehicle |
| 14 | van/SUV |
We will train our detector to specifically detect cars since that’s the most common class in our dataset (32616 of the 42816 total objects in the dataset are labeled as cars).
Solution overview
In this series, we cover how to visualize and label your data with Amazon SageMaker Ground Truth and demonstrate how to use this data in an Amazon SageMaker training job to create an object detection model, deployed to an Amazon SageMaker Endpoint. In particular, we’ll use an Amazon SageMaker notebook to operate the solution and launch any labeling or training jobs.
The following diagram depicts the overall flow of sensor data from labeling to training to deployment:

You’ll learn how to train and deploy a real-time 3D object detection model with Amazon SageMaker Ground Truth with the following steps:
- Download and visualize a point cloud dataset
- Prep data to be labeled with the Amazon SageMaker Ground Truth point cloud tool
- Launch a distributed Amazon SageMaker Ground Truth training job with MMDetection3D
- Evaluate your training job results and profiling your resource utilization with Amazon SageMaker Debugger
- Deploy an asynchronous SageMaker endpoint
- Call the endpoint and visualizing 3D object predictions
AWS services used to Implement this solution
- Amazon SageMaker Ground Truth
- Amazon SageMaker Training
- Amazon SageMaker Inference
- Amazon SageMaker Notebooks
- Amazon FSx for Lustre
- Amazon Simple Storage Service (Amazon S3)
Prerequisites
- An AWS account.
- Familiarity with Amazon SageMaker Ground Truth and AWS CloudFormation
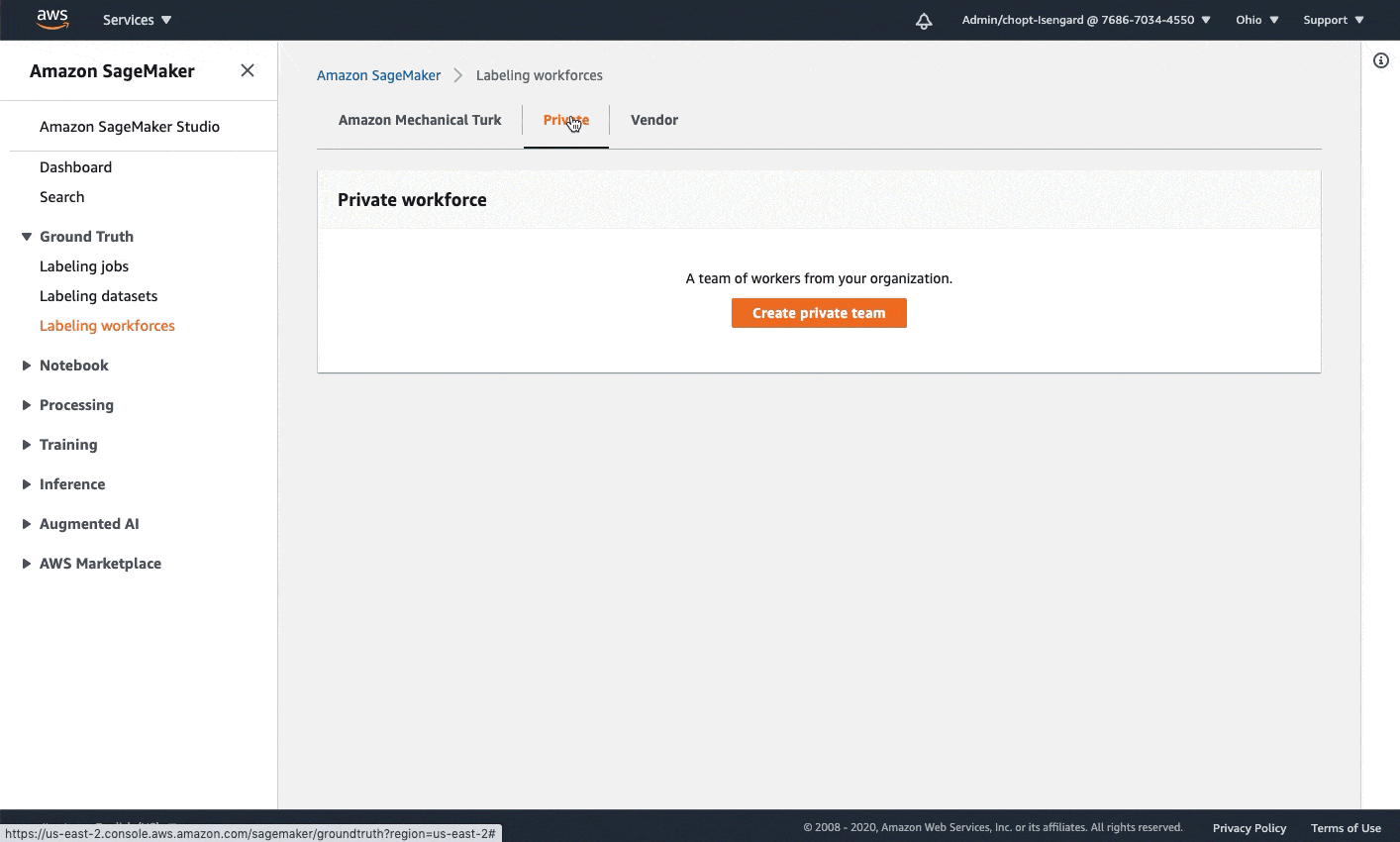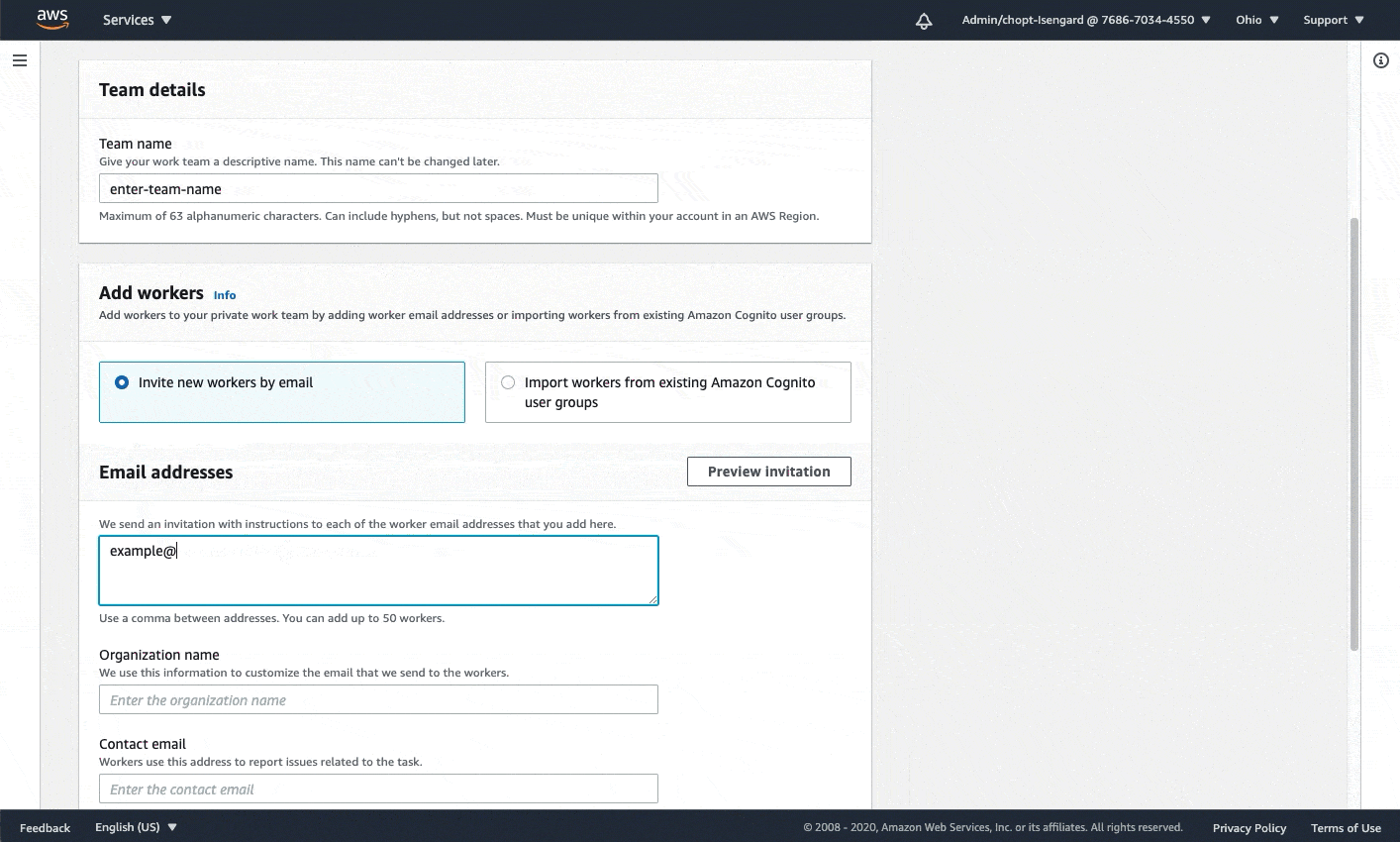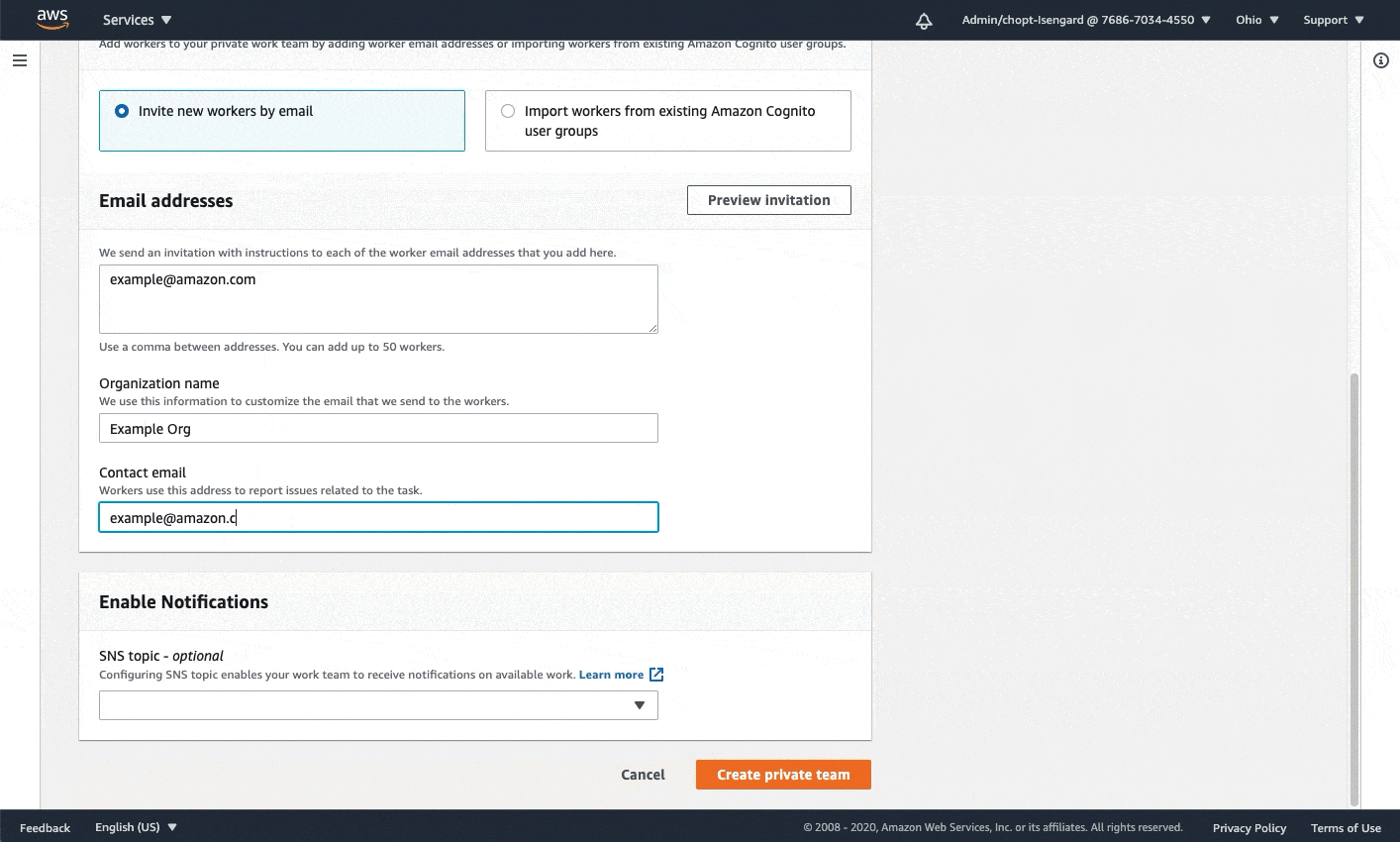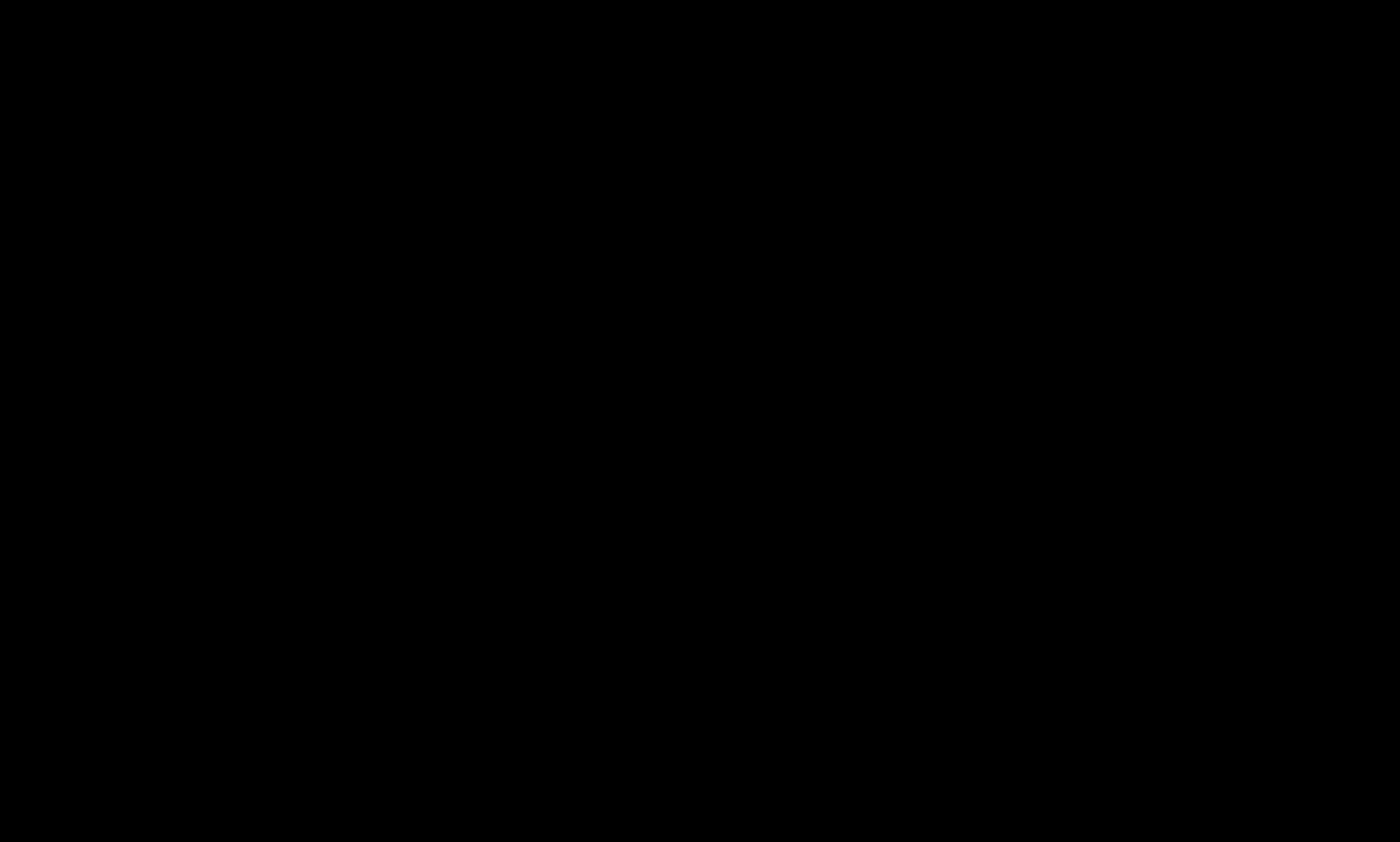
- An Amazon SageMaker workforce. For this demonstration, we use a private workforce. You can create a workforce through the SageMaker console.
The following diagram demonstrates how to create a private workforce. For written, step-by-step instructions, see Create an Amazon Cognito Workforce Using the Labeling Workforces Page.
Launching the AWS CloudFormation stack
Now that you’ve seen the structure of the solution, you deploy it into your account so you can run an example workflow. All the deployment steps related to the labeling pipeline are managed by AWS CloudFormation. This means AWS Cloudformation creates your notebook instance as well as any roles or Amazon S3 Buckets to support running the solution.
You can launch the stack in AWS Region us-east-1 on the AWS CloudFormation console using the Launch Stack
button. To launch the stack in a different Region, use the instructions found in the README of the GitHub repository.
![]()
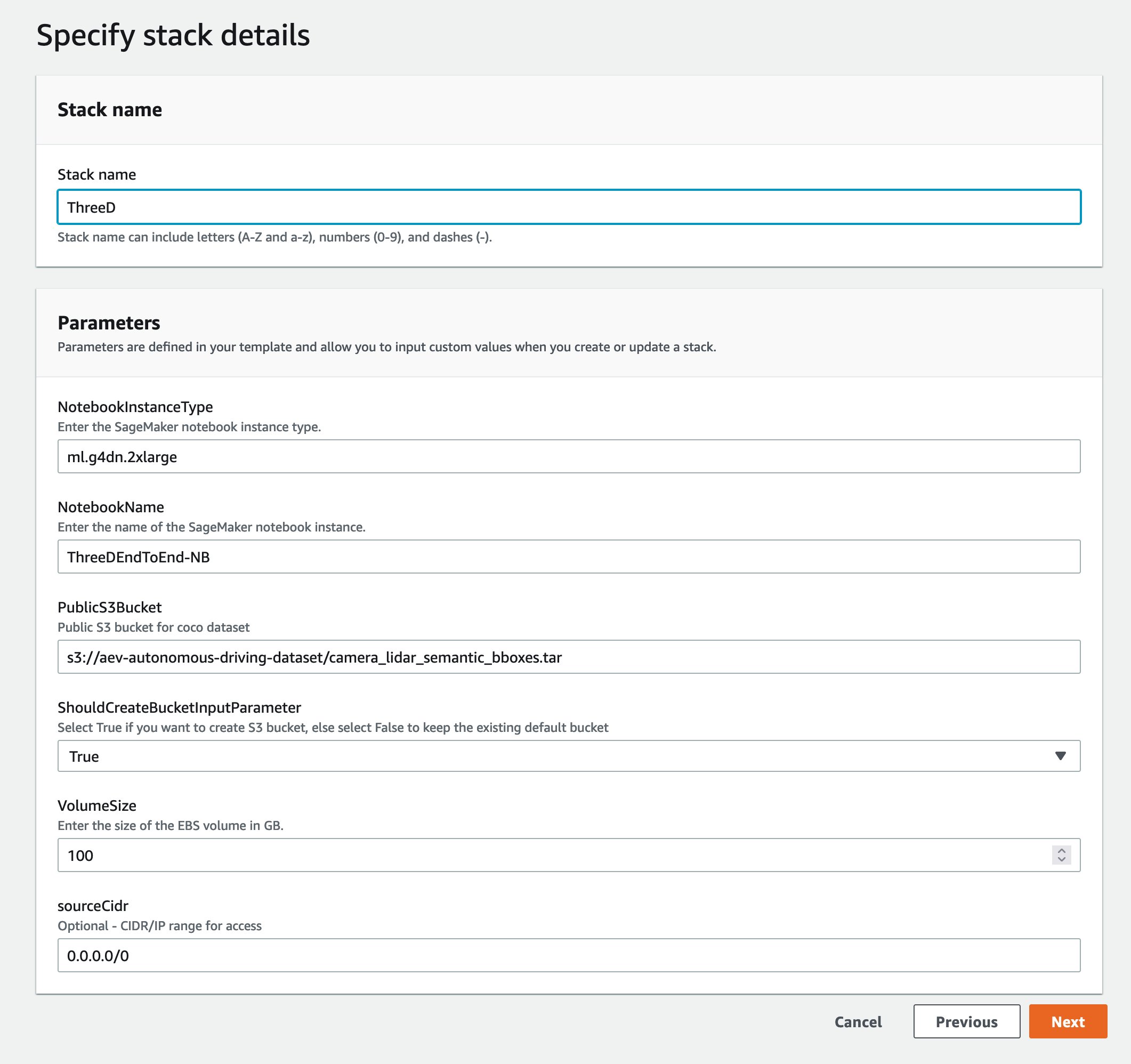
This takes approximately 20 minutes to create all the resources. You can monitor the progress from the AWS CloudFormation user interface (UI).
Once your CloudFormation template is done running go back to the AWS Console.
Opening the Notebook
Amazon SageMaker Notebook Instances are ML compute instances that run on the Jupyter Notebook App. Amazon SageMaker manages the creation of instances and related resources. Use Jupyter notebooks in your notebook instance to prepare and process data, write code to train models, deploy models to Amazon SageMaker hosting, and test or validate your models.
Follow the next steps to access the Amazon SageMaker Notebook environment:
- Under services search for Amazon SageMaker.

- Under Notebook, select Notebook instances.

- A Notebook instance should be provisioned. Select Open JupyterLab, which is located on the right side of the pre-provisioned Notebook instance under Actions.

- You’ll see an icon like this as the page loads:

- You’ll be redirected to a new browser tab that looks like the following diagram:

- Once you are in the Amazon SageMaker Notebook Instance Launcher UI. From the left sidebar, select the Git icon as shown in the following diagram.

- Select Clone a Repository option.

- Enter GitHub URL(https://github.com/aws-samples/end-2-end-3d-ml) in the pop‑up window and choose clone.

- Select File Browser to see the GitHub folder.

- Open the notebook titled
1_visualization.ipynb.
Operating the Notebook
Overview
The first few cells of the notebook in the section titled Downloaded Files walks through how to download the dataset and inspect the files within it. After the cells are executed, it takes a few minutes for the data to finish downloading.
Once downloaded, you can review the file structure of A2D2, which is a list of scenes or drives. A scene is a short recording of sensor data from our vehicle. A2D2 provides 18 of these scenes for us to train on, which are all identified by unique dates. Each scene contains 2D camera data, 2D labels, 3D cuboid annotations, and 3D point clouds.
You can view the file structure for the A2D2 dataset with the following:
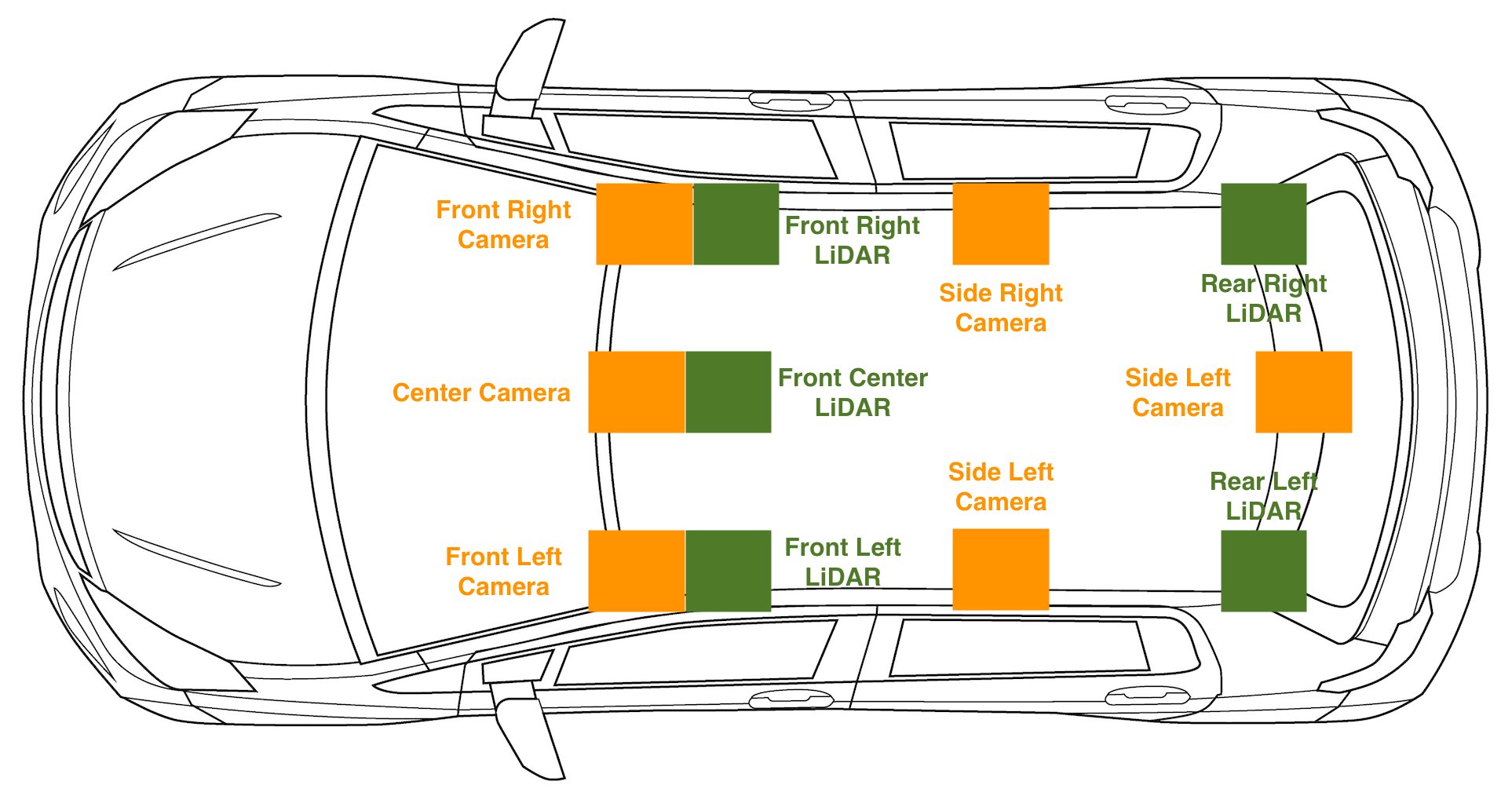
A2D2 sensor setup
The next section walks through reading some of this point cloud data to make sure we’re interpreting it correctly and can visualize it in the notebook before trying to convert it into a format ready for data labeling.
For any kind of autonomous driving setup where we have 2D and 3D sensor data, capturing sensor calibration data is essential. In addition to the raw data, we also downloaded cams_lidar.json. This file contains the translation and orientation of each sensor relative to the vehicle’s coordinate frame, this can also be referred to as the sensor’s pose, or location in space. This is important for converting points from a sensor’s coordinate frame to the vehicle’s coordinate frame. In other words, it’s important for visualizing the 2D and 3D sensors as the vehicle drives. The vehicle’s coordinate frame is defined as a static point in the center of the vehicle, with the x-axis in the direction of the forward movement of the vehicle, the y-axis denoting left and right with left being positive, and the z-axis pointing through the roof of the vehicle. A point (X,Y,Z) of (5,2,1) means this point is 5 meters ahead of our vehicle, 2 meters to the left, and 1 meter above our vehicle. Having these calibrations also allows us to project 3D points onto our 2D image, which is especially helpful for point cloud labeling tasks.
To see the sensor setup on the vehicle, check the following diagram.
The point cloud data we are training on is specifically aligned with the front facing camera or cam front-center:
This matches our visualization of camera sensors in 3D:

This portion of the notebook walks through validating that the A2D2 dataset matches our expectations about sensor positions, and that we’re able to align data from the point cloud sensors into the camera frame. Feel free to run all cells through the one titled Projection from 3D to 2D to see your point cloud data overlay on the following camera image.

Conversion to Amazon SageMaker Ground Truth

After visualizing our data in our notebook, we can confidently convert our point clouds into Amazon SageMaker Ground Truth’s 3D format to verify and adjust our labels. This section walks through converting from A2D2’s data format into an Amazon SageMaker Ground Truth sequence file, with the input format used by the object tracking modality.
The sequence file format includes the point cloud formats, the images associated with each point cloud, and all sensor position and orientation data required to align images with point clouds. These conversions are done using the sensor information read from the previous section. The following example is a sequence file format from Amazon SageMaker Ground Truth, which describes a sequence with only a single timestep.
The point cloud for this timestep is located at s3://sagemaker-us-east-1-322552456788/a2d2_smgt/20180807_145028_out/20180807145028_lidar_frontcenter_000000091.txt and has a format of <x coordinate> <y coordinate> <z coordinate>.
Associated with the point cloud, is a single camera image located at s3://sagemaker-us-east-1-322552456788/a2d2_smgt/20180807_145028_out/undistort_20180807145028_camera_frontcenter_000000091.png. Notice that we take the sequence file that defines all camera parameters to allow projection from the point cloud to the camera and back.
Conversion to this input format requires us to write a conversion from A2D2’s data format to data formats supported by Amazon SageMaker Ground Truth. This is the same process anyone must undergo when bringing their own data for labeling. We’ll walk through how this conversion works, step-by-step. If following along in the notebook, look at the function named a2d2_scene_to_smgt_sequence_and_seq_label.
Point cloud conversion
The first step is to convert the data from a compressed Numpy-formatted file (NPZ), which was generated with the numpy.savez method, to an accepted raw 3D format for Amazon SageMaker Ground Truth. Specifically, we generate a file with one row per point. Each 3D point is defined by three floating point X, Y, and Z coordinates. When we specify our format in the sequence file, we use the string text/xyz to represent this format. Amazon SageMaker Ground Truth also supports adding intensity values or Red Green Blue (RGB) points.
A2D2’s NPZ files contain multiple Numpy arrays, each with its own name. To perform a conversion, we load the NPZ file using Numpy’s load method, access the array called points (i.e., an Nx3 array, where N is the number of points in the point cloud), and save as text to a new file using Numpy’s savetxt method.
Image preprocessing
Next, we prepare our image files. A2D2 provides PNG images, and Amazon SageMaker Ground Truth supports PNG images; however, these images are distorted. Distortion often occurs because the image-taking lens is not aligned parallel to the imaging plane, which makes some areas in the image look closer than expected. This distortion describes the difference between a physical camera and an idealized pinhole camera model. If distortion isn’t taken into account, then Amazon SageMaker Ground Truth won’t be able to render our 3D points on top of the camera views, which makes it more challenging to perform labeling. For a tutorial on camera calibration, look at this documentation from OpenCV.
While Amazon SageMaker Ground Truth supports distortion coefficients in its input file, you can also perform preprocessing before the labeling job. Since A2D2 provides helper code to perform undistortion, we apply it to the image, and leave the fields related to distortion out of our sequence file. Note that the distortion related fields include k1, k2, k3, k4, p1, p2, and skew.
Camera position, orientation, and projection conversion
Beyond the raw data files required for labeling, the sequence file also requires camera position and orientation information to perform the projection of 3D points into the 2D camera views. We need to know where the camera is looking in 3D space to figure out how 3D cuboid labels and 3D points should be rendered on top of our images.
Because we’ve loaded our sensor positions into a common transform manager in the A2D2 sensor setup section, we can easily query the transform manager for the information we want. In our case, we treat the vehicle position as (0, 0, 0) in each frame because we don’t have position information of the sensor provided by A2D2’s object detection dataset. So relative to our vehicle, the camera’s orientation and position is described by the following code:
Now that position and orientation are converted, we also need to supply values for fx, fy, cx, and cy, all parameters for each camera in the sequence file format.
These parameters refer to values in the camera matrix. While the position and orientation describe which way a camera is facing, the camera matrix describes the field of the view of the camera and exactly how a 3D point relative to the camera gets converted to a 2D pixel location in an image.
A2D2 provides a camera matrix. A reference camera matrix is shown in the following code, along with how our notebook indexes this matrix to get the appropriate fields.
With all of the fields parsed from A2D2’s format, we can save the sequence file and use it in an Amazon SageMaker Ground Truth input manifest file to start a labeling job. This labeling job allows us to create 3D bounding box labels to use downstream for 3D model training.
Run all cells until the end of the notebook, and ensure you replace the workteam ARN with the Amazon SageMaker Ground Truth workteam ARN you created a prerequisite. After about 10 minutes of labeling job creation time, you should be able to login to the worker portal and use the labeling user interface to visualize your scene.
Clean up
Delete the AWS CloudFormation stack you deployed using the Launch Stack button named ThreeD in the AWS CloudFormation console to remove all resources used in this post, including any running instances.
Estimated costs
The approximate cost is $5 for 2 hours.
Conclusion
In this post, we demonstrated how to take 3D data and convert it into a form ready for labeling in Amazon SageMaker Ground Truth. With these steps, you can label your own 3D data for training object detection models. In the next post in this series, we’ll show you how to take A2D2 and train an object detector model on the labels already in the dataset.
Happy Building!
About the Authors
 Isaac Privitera is a Senior Data Scientist at the Amazon Machine Learning Solutions Lab, where he develops bespoke machine learning and deep learning solutions to address customers’ business problems. He works primarily in the computer vision space, focusing on enabling AWS customers with distributed training and active learning.
Isaac Privitera is a Senior Data Scientist at the Amazon Machine Learning Solutions Lab, where he develops bespoke machine learning and deep learning solutions to address customers’ business problems. He works primarily in the computer vision space, focusing on enabling AWS customers with distributed training and active learning.
 Vidya Sagar Ravipati is Manager at the Amazon Machine Learning Solutions Lab, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption. Previously, he was a Machine Learning Engineer in Connectivity Services at Amazon who helped to build personalization and predictive maintenance platforms.
Vidya Sagar Ravipati is Manager at the Amazon Machine Learning Solutions Lab, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption. Previously, he was a Machine Learning Engineer in Connectivity Services at Amazon who helped to build personalization and predictive maintenance platforms.
 Jeremy Feltracco is a Software Development Engineer with th Amazon Machine Learning Solutions Lab at Amazon Web Services. He uses his background in computer vision, robotics, and machine learning to help AWS customers accelerate their AI adoption.
Jeremy Feltracco is a Software Development Engineer with th Amazon Machine Learning Solutions Lab at Amazon Web Services. He uses his background in computer vision, robotics, and machine learning to help AWS customers accelerate their AI adoption.