
Businesses are increasingly using machine learning (ML) to make near-real-time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products and services. ML models make predictions given a set of input data known as features, and data scientists easily spend more than 60% of their time designing and building these features. Furthermore, highly accurate predictions depend on timely access to feature values that change quickly over time, adding even more complexity to the job of building a highly available and accurate solution. For example, a model for a ride-sharing app can choose the best price for a ride from the airport, but only if it knows the number of ride requests received in the past 10 minutes and the number of passengers projected to land in the next 10 minutes. A routing model in a call center app can pick the best available agent for an incoming call, but it’s only effective if it knows the customer’s latest web session clicks.
Although the business value of near-real-time ML predictions is enormous, the architecture required to deliver them reliably, securely, and with good performance is complicated. Solutions need high-throughput updates and low-latency retrieval of the most recent feature values in milliseconds, something most data scientists aren’t prepared to deliver. As a result, some enterprises have spent millions of dollars inventing their own proprietary infrastructure for feature management. Other firms have limited their ML applications to simpler patterns like batch scoring until ML vendors provide more comprehensive off-the-shelf solutions for online feature stores.
To address these challenges, Amazon SageMaker Feature Store provides a fully managed central repository for ML features, making it easy to securely store and retrieve features without having to build and maintain your own infrastructure. Feature Store lets you define groups of features, use batch ingestion and streaming ingestion, retrieve the latest feature values with single-digit millisecond latency for highly accurate online predictions, and extract point-in-time correct datasets for training. Instead of building and maintaining these infrastructure capabilities, you get a fully managed service that scales as your data grows, enables sharing features across teams, and lets your data scientists focus on building great ML models aimed at game-changing business use cases. Teams can now deliver robust features once and reuse them many times in a variety of models that may be built by different teams.
This post walks through a complete example of how you can couple streaming feature engineering with Feature Store to make ML-backed decisions in near-real time. We show a credit card fraud detection use case that updates aggregate features from a live stream of transactions and uses low-latency feature retrievals to help detect fraudulent transactions. Try it out for yourself by visiting our GitHub repo.
Credit card fraud use case
Stolen credit card numbers can be bought in bulk on the dark web from previous leaks or hacks of organizations that store this sensitive data. Fraudsters buy these card lists and attempt to make as many transactions as possible with the stolen numbers until the card is blocked. These fraud attacks typically happen in a short time frame, and this can be easily spotted in historical transactions because the velocity of transactions during the attack differs significantly from the cardholder’s usual spending pattern.
The following table shows a sequence of transactions from one credit card where the cardholder first has a genuine spending pattern, and then experiences a fraud attack starting on November 4.
| cc_num | trans_time | amount | fraud_label |
| …1248 | Nov-01 14:50:01 | 10.15 | 0 |
| … 1248 | Nov-02 12:14:31 | 32.45 | 0 |
| … 1248 | Nov-02 16:23:12 | 3.12 | 0 |
| … 1248 | Nov-04 02:12:10 | 1.01 | 1 |
| … 1248 | Nov-04 02:13:34 | 22.55 | 1 |
| … 1248 | Nov-04 02:14:05 | 90.55 | 1 |
| … 1248 | Nov-04 02:15:10 | 60.75 | 1 |
| … 1248 | Nov-04 13:30:55 | 12.75 | 0 |
For this post, we train an ML model to spot this kind of behavior by engineering features that describe an individual card’s spending pattern, such as the number of transactions or the average transaction amount from that card in a certain time window. This model protects cardholders from fraud at the point of sale by detecting and blocking suspicious transactions before the payment can complete. The model makes predictions in a low-latency, real-time context and relies on receiving up-to-the-minute feature calculations so it can respond to an ongoing fraud attack. In a real-world scenario, features related to cardholder spending patterns would only form part of the model’s feature set, and we can include information about the merchant, the cardholder, the device used to make the payment, and any other data that may be relevant to detecting fraud.
Because our use case relies on profiling an individual card’s spending patterns, it’s crucial that we can identify credit cards in a transaction stream. Most publicly available fraud detection datasets don’t provide this information, so we use the Python Faker library to generate a set of transactions covering a 5-month period. This dataset contains 5.4 million transactions spread across 10,000 unique (and fake) credit card numbers, and is intentionally imbalanced to match the reality of credit card fraud (only 0.25% of the transactions are fraudulent). We vary the number of transactions per day per card, as well as the transaction amounts. See our GitHub repo for more details.
Overview of the solution
We want our fraud detection model to classify credit card transactions by noticing a burst of recent transactions that differs significantly from the cardholder’s usual spending pattern. Sounds simple enough, but how do we build it?
The following diagram shows our overall solution architecture. We feel that this same pattern will work well for a variety of streaming aggregation use cases. At a high level, the pattern involves the following five pieces:
- Feature store – We use Feature Store to provide a repository of features with high-throughput writes and secure low-latency reads, using feature values that are organized into multiple feature groups.
- Batch ingestion – Batch ingestion takes labeled historical credit card transactions and creates the aggregate features and ratios needed for training the fraud detection model. We use an Amazon SageMaker Processing job and the built-in Spark container to calculate aggregate weekly counts and transaction amount averages and ingest them into the feature store for use in online inference.
- Model training and deployment – This aspect of our solution is straightforward. We use Amazon SageMaker to train a model using the built-in XGBoost algorithm on aggregated features created from historical transactions. The model is deployed to a SageMaker endpoint, where it handles fraud detection requests on live transactions.
- Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink application backed by Apache Kafka topics in Amazon Managed Streaming for Apache Kafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store. Apache Flink is a popular framework and engine for processing data streams.
- Streaming predictions – Lastly, we make fraud predictions on a stream of transactions, using Lambda to pull aggregate features from the online feature store. We use the latest feature data to calculate transaction ratios and then call the fraud detection endpoint.
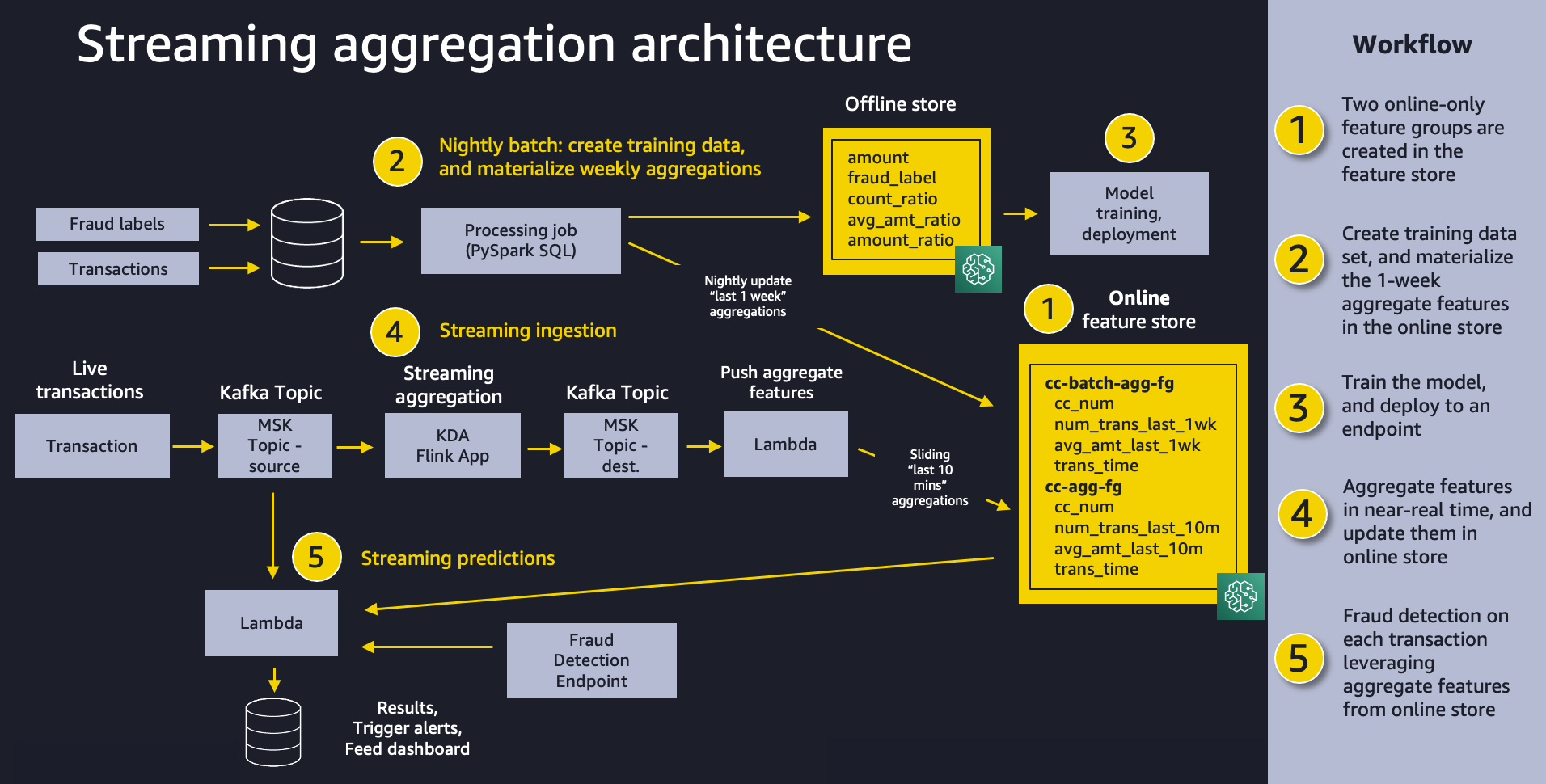
Prerequisites
We provide an AWS CloudFormation template to create the prerequisite resources for this solution. The following table lists the stacks available for different Regions.
| AWS Region | Link |
| us-east-1 | |
| us-east-2 | |
| us-west-1 | |
| eu-west-1 | |
| ap-northeast-1 |
In the following sections, we explore each component of our solution in more detail.
Feature store
ML models rely on well-engineered features coming from a variety of data sources, with transformations as simple as calculations or as complicated as a multi-step pipeline that takes hours of compute time and complex coding. Feature Store enables the reuse of these features across teams and models, which improves data scientist productivity, speeds up time to market, and ensures consistency of model input.
Each feature inside Feature Store is organized into a logical grouping called a feature group. You decide which feature groups you need for your models. Each one can have dozens, hundreds, or even thousands of features. Feature groups are managed and scaled independently, but they’re all available for search and discovery across teams of data scientists responsible for many independent ML models and use cases.
ML models often require features from multiple feature groups. A key aspect of a feature group is how often its feature values need to be updated or materialized for downstream training or inference. You refresh some features hourly, nightly, or weekly, and a subset of features must be streamed to the feature store in near-real time. Streaming all feature updates would lead to unnecessary complexity, and could even lower the quality of data distributions by not giving you the chance to remove outliers.
In our use case, we create a feature group called cc-agg-batch-fg for aggregated credit card features updated in batch, and one called cc-agg-fg for streaming features.
The cc-agg-batch-fg feature group is updated nightly, and provides aggregate features looking back over a 1-week time window. Recalculating 1-week aggregations on streaming transactions don’t offer meaningful signals, and would be a waste of resources.
Conversely, our cc-agg-fg feature group must be updated in a streaming fashion, because it offers the latest transaction counts and average transaction amounts looking back over a 10-minute time window. Without streaming aggregation, we couldn’t spot the typical fraud attack pattern of a rapid sequence of purchases.
By isolating features that are recalculated nightly, we can improve ingestion throughput for our streaming features. Separation lets us optimize the ingestion for each group independently. When designing for your use cases, keep in mind that models requiring features from a large number of feature groups may want to make multiple retrievals from the feature store in parallel to avoid adding excessive latency to a real-time prediction workflow.
The feature groups for our use case are shown in the following table.
| cc-agg-fg | cc-agg-batch-fg |
| cc_num (record id) | cc_num (record id) |
| trans_time | trans_time |
| num_trans_last_10m | num_trans_last_1w |
| avg_amt_last_10m | avg_amt_last_1w |
Each feature group must have one feature used as a record identifier (for this post, the credit card number). The record identifier acts as a primary key for the feature group, enabling fast lookups as well as joins across feature groups. An event time feature is also required, which enables the feature store to track the history of feature values over time. This becomes important when looking back at the state of features at a specific point in time.
In each feature group, we track the number of transactions per unique credit card and its average transaction amount. The only difference between our two groups is the time window used for aggregation. We use a 10-minute window for streaming aggregation, and a 1-week window for batch aggregation.
With Feature Store, you have the flexibility to create feature groups that are offline only, online only, or both online and offline. An online store provides high-throughput writes and low-latency retrievals of feature values, which is ideal for online inference. An offline store is provided using Amazon Simple Storage Service (Amazon S3), giving firms a highly scalable repository, with a full history of feature values, partitioned by feature group. The offline store is ideal for training and batch scoring use cases.
When you enable a feature group to provide both online and offline stores, SageMaker automatically synchronizes feature values to an offline store, continuously appending the latest values to give you a full history of values over time. Another benefit of feature groups that are both online and offline is that they help avoid the problem of training and inference skew. SageMaker lets you feed both training and inference with the same transformed feature values, ensuring consistency to drive more accurate predictions. The focus in our post is to demonstrate online feature streaming, so we implemented online-only feature groups.
Batch ingestion
To materialize our batch features, we create a feature pipeline that runs as a SageMaker Processing job on a nightly basis. The job has two responsibilities: producing the dataset for training our model, and populating the batch feature group with the most up-to-date values for aggregate 1-week features, as shown in the following diagram.

Each historical transaction used in the training set is enriched with aggregated features for the specific credit card involved in the transaction. We look back over two separate sliding time windows: 1 week back, and the preceding 10 minutes. The actual features used to train the model include the following ratios of these aggregated values:
- amt_ratio1 =
avg_amt_last_10m / avg_amt_last_1w - amt_ratio2 =
transaction_amount / avg_amt_last_1w - count_ratio =
num_trans_last_10m / num_trans_last_1w
For example, count_ratio is the transaction count from the prior 10 minutes divided by the transaction count from the last week.
Our ML model can learn patterns of normal activity vs. fraudulent activity from these ratios, rather than relying on raw counts and transaction amounts. Spending patterns on different cards vary greatly, so normalized ratios provide a better signal to the model than the aggregated amounts themselves.
You may be wondering why our batch job is computing features with a 10-minute lookback. Isn’t that only relevant for online inference? We need the 10-minute window on historical transactions to create an accurate training dataset. This is critical for ensuring consistency with the 10-minute streaming window that will be used in near-real time to support online inference.
The resulting training dataset from the processing job can be saved directly as a CSV for model training, or it can be bulk ingested into an offline feature group that can be used for other models and by other data science teams to address a wide variety of other use cases. For example, we can create and populate a feature group called cc-transactions-fg. Our training job can then pull a specific training dataset based on the needs for our specific model, selecting specific date ranges and a subset of features of interest. This approach enables multiple teams to reuse feature groups and maintain fewer feature pipelines, leading to significant cost savings and productivity improvements over time. This example notebook demonstrates the pattern of using Feature Store as a central repository from which data scientists can extract training datasets.
In addition to creating a training dataset, we use the PutRecord API to put the 1-week feature aggregations into the online feature store nightly. The following code demonstrates putting a record into an online feature group given specific feature values, including a record identifier and an event time:
ML engineers often build a separate version of feature engineering code for online features based on the original code written by data scientists for model training. This can deliver the desired performance, but is an extra development step, and introduces more chance for training and inference skew. In our use case, we show how using SQL for aggregations can enable a data scientist to provide the same code for both batch and streaming.
Streaming ingestion
Feature Store delivers single-digit millisecond retrieval of pre-calculated features, and it can also play an effective role in solutions requiring streaming ingestion. Our use case demonstrates both. Weekly lookback is handled as a pre-calculated feature group, materialized nightly as shown earlier. Now let’s dive into how we calculate features aggregated on the fly over a 10-minute window and ingest them into the feature store for later online inference.
In our use case, we ingest live credit card transactions to a source MSK topic, and use a Kinesis Data Analytics for Apache Flink application to create aggregate features in a destination MSK topic. The application is written using Apache Flink SQL. Flink SQL makes it simple to develop streaming applications using standard SQL. It’s easy to learn Flink if you have ever worked with a database or SQL-like system by remaining ANSI-SQL 2011 compliant. Apart from SQL, we can build Java and Scala applications in Amazon Kinesis Data Analytics using open-source libraries based on Apache Flink. We then use a Lambda function to read the destination MSK topic and ingest the aggregate features into a SageMaker feature group for inference. Creating the Apache Flink application using Flink’s SQL API is straightforward. We use Flink SQL to aggregate the streaming data in the source MSK topic and store it in a destination MSK topic.
To produce aggregate counts and average amounts looking back over a 10-minute window, we use the following Flink SQL query on the input topic and pipe the results to the destination topic:
| cc_num | amount | datetime | num_trans_last_10m | avg_amt_last_10m |
| …1248 | 50.00 | Nov-01,22:01:00 | 1 | 74.99 |
| …9843 | 99.50 | Nov-01,22:02:30 | 1 | 99.50 |
| …7403 | 100.00 | Nov-01,22:03:48 | 1 | 100.00 |
| …1248 | 200.00 | Nov-01,22:03:59 | 2 | 125.00 |
| …0732 | 26.99 | Nov01, 22:04:15 | 1 | 26.99 |
| …1248 | 50.00 | Nov-01,22:04:28 | 3 | 100.00 |
| …1248 | 500.00 | Nov-01,22:05:05 | 4 | 200.00 |
In this example, notice that the final row has a count of four transactions in the last 10 minutes from the credit card ending with 1248, and a corresponding average transaction amount of $200.00. The SQL query is consistent with the one used to drive creation of our training dataset, helping to avoid training and inference skew.
As transactions stream into the Kinesis Data Analytics for Apache Flink aggregation app, the app sends the aggregate results to our Lambda function, as shown in the following diagram. The Lambda function takes these features and populates the cc-agg-fg feature group.

We send the latest feature values to the feature store from Lambda using a simple call to the PutRecord API. The following is the core piece of Python code for storing the aggregate features:
We prepare the record as a list of named value pairs, including the current time as the event time. The Feature Store API ensures that this new record follows the schema that we identified when we created the feature group. If a record for this primary key already existed, it is now overwritten in the online store.
Streaming predictions
Now that we have streaming ingestion keeping the feature store up to date with the latest feature values, let’s look at how we make fraud predictions.
We create a second Lambda function that uses the source MSK topic as a trigger. For each new transaction event, the Lambda function first retrieves the batch and streaming features from Feature Store. To detect anomalies in credit card behavior, our model looks for spikes in recent purchase amounts or purchase frequency. The Lambda function computes simple ratios between the 1-week aggregations and the 10-minute aggregations. It then invokes the SageMaker model endpoint using those ratios to make the fraud prediction, as shown in the following diagram.

We use the following code to retrieve feature values on demand from the feature store before calling the SageMaker model endpoint:
SageMaker also supports retrieving multiple feature records with a single call, even if they are from different feature groups.
Finally, with the model input feature vector assembled, we call the model endpoint to predict if a specific credit card transaction is fraudulent. SageMaker also supports retrieving multiple feature records with a single call, even if they are from different feature groups.
sagemaker_runtime =
boto3.client(service_name='runtime.sagemaker')
request_body = ','.join(features)
response = sagemaker_runtime.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType='text/csv',
Body=request_body)
probability = json.loads(response['Body'].read().decode('utf-8'))In this example, the model came back with a probability of 98% that the specific transaction was fraudulent, and it was able to use near-real-time aggregated input features based on the most recent 10 minutes of transactions on that credit card.
Test the end-to-end solution
To demonstrate the full end-to-end workflow of our solution, we simply send credit card transactions into our MSK source topic. Our automated Kinesis Data Analytics for Apache Flink aggregation takes over from there, maintaining a near-real-time view of transaction counts and amounts in Feature Store, with a sliding 10-minute lookback window. These features are combined with the 1-week aggregate features that were already ingested to the feature store in batch, letting us make fraud predictions on each transaction.
We send a single transaction from three different credit cards. We then simulate a fraud attack on a fourth credit card by sending many back-to-back transactions in seconds. The output from our Lambda function is shown in the following screenshot. As expected, the first three one-off transactions are predicted as NOT FRAUD. Of the 10 fraudulent transactions, the first is predicted as NOT FRAUD, and the rest are all correctly identified as FRAUD. Notice how the aggregate features are kept current, helping drive more accurate predictions.

Conclusion
We have shown how Feature Store can play a key role in the solution architecture for critical operational workflows that need streaming aggregation and low-latency inference. With an enterprise-ready feature store in place, you can use both batch ingestion and streaming ingestion to feed feature groups, and access feature values on demand to perform online predictions for significant business value. ML features can now be shared at scale across many teams of data scientists and thousands of ML models, improving data consistency, model accuracy, and data scientist productivity. Feature Store is available now, and you can try out this entire example. Let us know what you think.
Special thanks to everyone who contributed to the previous blog post with a similar architecture: Paul Hargis, James Leoni and Arunprasath Shankar.
About the Authors
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in feature stores, computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in feature stores, computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
 Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
 Prabhakar Chandrasekaran is a Senior Technical Account Manager with AWS Enterprise Support. Prabhakar enjoys helping customers build cutting-edge AI/ML solutions on the cloud. He also works with enterprise customers providing proactive guidance and operational assistance, helping them improve the value of their solutions when using AWS. Prabhakar holds six AWS and six other professional certifications. With over 20 years of professional experience, Prabhakar was a data engineer and a program leader in the financial services space prior to joining AWS.
Prabhakar Chandrasekaran is a Senior Technical Account Manager with AWS Enterprise Support. Prabhakar enjoys helping customers build cutting-edge AI/ML solutions on the cloud. He also works with enterprise customers providing proactive guidance and operational assistance, helping them improve the value of their solutions when using AWS. Prabhakar holds six AWS and six other professional certifications. With over 20 years of professional experience, Prabhakar was a data engineer and a program leader in the financial services space prior to joining AWS.