In the era of big data and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. One of the hottest areas in AI right now is generative AI, and for good reason. Generative AI offers powerful solutions that push the boundaries of what’s possible in terms of creativity and innovation. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data. Many of these foundation models have shown remarkable capability in understanding and generating human-like text, making them a valuable tool for a variety of applications, from content creation to customer support automation.
However, these models are not without their challenges. They are exceptionally large and require large amounts of data and computational resources to train. Additionally, optimizing the training process and calibrating the parameters can be a complex and iterative process, requiring expertise and careful experimentation. These can be barriers for many organizations looking to build their own foundation models. To overcome this challenge, many customers are considering to fine-tune existing foundation models. This is a popular technique to adjust a small portion of model parameters for specific applications while still preserving the knowledge already encoded in the model. It allows organizations to use the power of these models while reducing the resources required to customize to a specific domain or task.
There are two primary approaches to fine-tuning foundation models: traditional fine-tuning and parameter-efficient fine-tuning. Traditional fine-tuning involves updating all the parameters of the pre-trained model for a specific downstream task. On the other hand, parameter-efficient fine-tuning includes a variety of techniques that allow for customization of a model without updating all the original model parameters. One such technique is called Low-rank Adaptation (LoRA). It involves adding small, task-specific modules to the pre-trained model and training them while keeping the rest of the parameters fixed as shown in the following image.
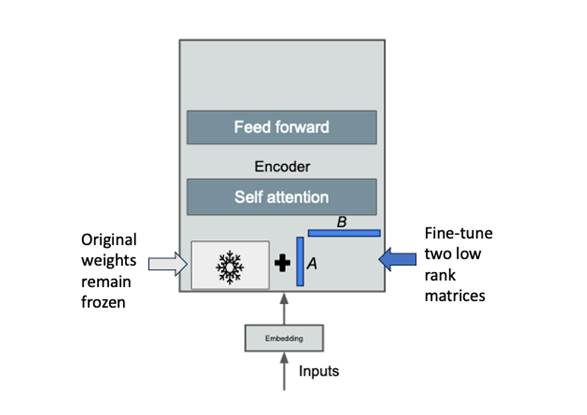
Source: Generative AI on AWS (O’Reilly, 2023)
LoRA has gained popularity recently for several reasons. It offers faster training, reduced memory requirements, and the ability to reuse pre-trained models for multiple downstream tasks. More importantly, the base model and adapter can be stored separately and combined at any time, making it easier to store, distribute, and share fine-tuned versions. However, this introduces a new challenge: how to properly manage these new types of fine-tuned models. Should you combine the base model and adapter or keep them separate? In this post, we walk through best practices for managing LoRA fine-tuned models on Amazon SageMaker to address this emerging question.
Working with FMs on SageMaker Model Registry
In this post, we walk through an end-to-end example of fine-tuning the Llama2 large language model (LLM) using the QLoRA method. QLoRA combines the benefits of parameter efficient fine-tuning with 4-bit/8-bit quantization to further reduce the resources required to fine-tune a FM to a specific task or use case. For this, we will use the pre-trained 7 billion parameter Llama2 model and fine-tune it on the databricks-dolly-15k dataset. LLMs like Llama2 have billions of parameters and are pretrained on massive text datasets. Fine-tuning adapts an LLM to a downstream task using a smaller dataset. However, fine-tuning large models is computationally expensive. This is why we will use the QLoRA method to quantize the weights during finetuning to reduce this computation cost.
In our examples, you will find two notebooks (llm-finetune-combined-with-registry.ipynb and llm-finetune-separate-with-registry.ipynb). Each works through a different way to handle LoRA fine-tuned models as illustrated in the following diagram:
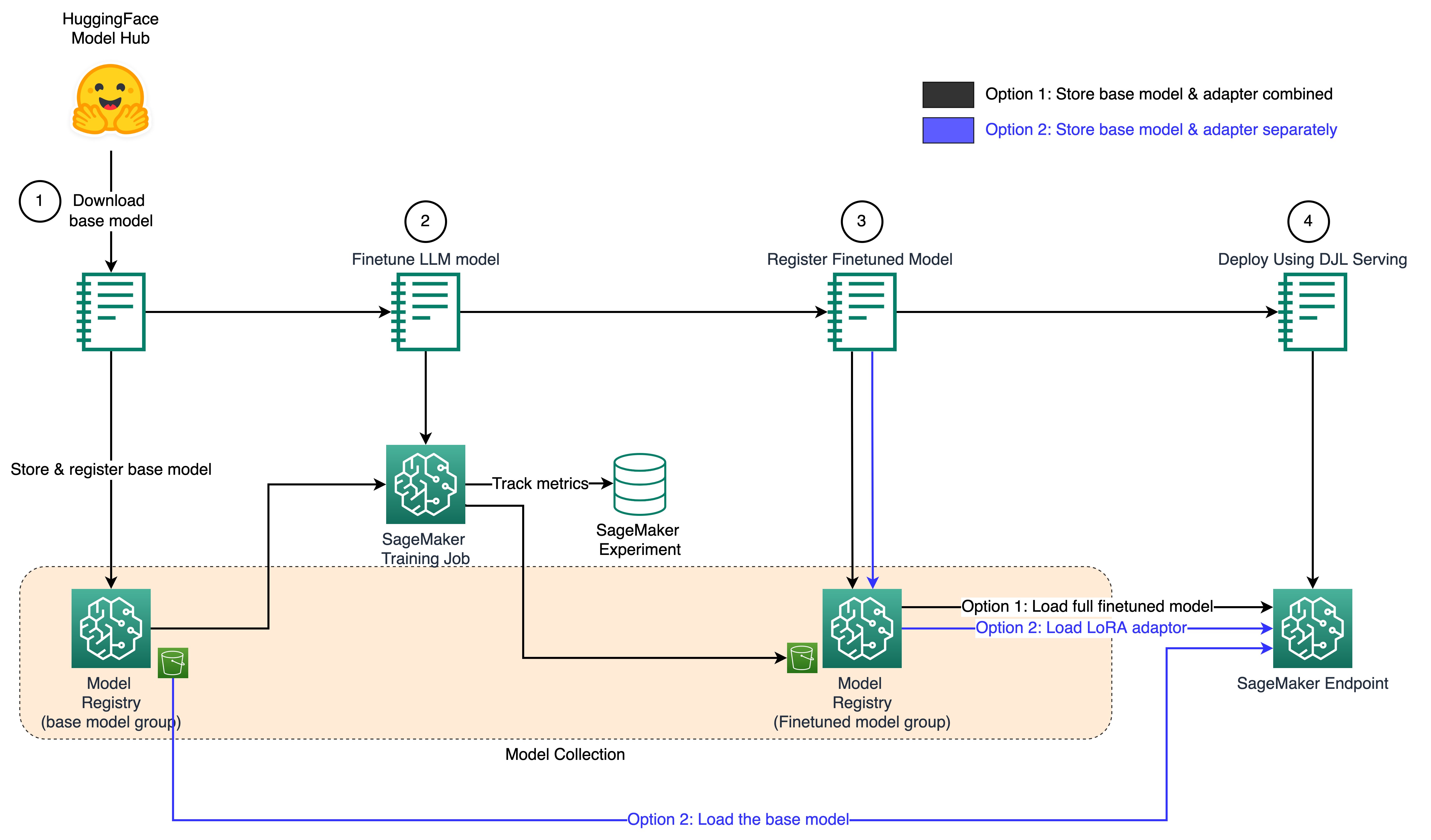
- First, we download the pre-trained Llama2 model with 7 billion parameters using SageMaker Studio Notebooks. LLMs, like Llama2, have shown state-of-the-art performance on natural language processing (NLP) tasks when fine-tuned on domain-specific data.
- Next, we fine-tune Llama2 on the databricks-dolly-15k dataset using the QLoRA method. QLoRA reduces the computational cost of fine-tuning by quantizing model weights.
- During fine-tuning, we integrate SageMaker Experiments Plus with the Transformers API to automatically log metrics like gradient, loss, etc.
- We then version the fine-tuned Llama2 model in SageMaker Model Registry using two approaches:
- Storing the full model
- Storing the adapter and base model separately.
- Finally, we host the fine-tuned Llama2 models using Deep Java Library (DJL) Serving on a SageMaker Real-time endpoint.
In the following sections, we will dive deeper into each of these steps, to demonstrate the flexibility of SageMaker for different LLM workflows and how these features can help improve the operations of your models.
Prerequisites
Complete the following prerequisites to start experimenting with the code.
- Create a SageMaker Studio Domain: Amazon SageMaker Studio, specifically Studio Notebooks, is used to kick off the Llama2 fine-tuning task then register and view models within SageMaker Model Registry. SageMaker Experiments is also used to view and compare Llama2 fine-tuning job logs (training loss/test loss/etc.).
- Create an Amazon Simple Storage Service (S3) bucket: Access to an S3 bucket to store training artifacts and model weights is required. For instructions, refer to Creating a bucket. The sample code used for this post will use the SageMaker default S3 bucket but you can customize it to use any relevant S3 bucket.
- Set up Model Collections (IAM permissions): Update your SageMaker Execution Role with permissions to resource-groups as listed under Model Registry Collections Developer Guide to implement Model Registry grouping using Model Collections.
- Accept the Terms & Conditions for Llama2: You will need to accept the end-user license agreement and acceptable use policy for using the Llama2 foundation model.
The examples are available in the GitHub repository. The notebook files are tested using Studio notebooks running on PyTorch 2.0.0 Python 3.10 GPU Optimized kernel and ml.g4dn.xlarge instance type.
Experiments plus callback integration
Amazon SageMaker Experiments lets you organize, track, compare and evaluate machine learning (ML) experiments and model versions from any integrated development environment (IDE), including local Jupyter Notebooks, using the SageMaker Python SDK or boto3. It provides the flexibility to log your model metrics, parameters, files, artifacts, plot charts from the different metrics, capture various metadata, search through them and support model reproducibility. Data scientists can quickly compare the performance and hyperparameters for model evaluation through visual charts and tables. They can also use SageMaker Experiments to download the created charts and share the model evaluation with their stakeholders.
Training LLMs can be a slow, expensive, and iterative process. It is very important for a user to track LLM experimentation at scale to prevent an inconsistent model tuning experience. HuggingFace Transformer APIs allow users to track metrics during training tasks through Callbacks. Callbacks are “read only” pieces of code that can customize the behavior of the training loop in the PyTorch Trainer that can inspect the training loop state for progress reporting, logging on TensorBoard or SageMaker Experiments Plus via custom logic (which is included as a part of this codebase).
You can import the SageMaker Experiments callback code included in this post’s code repository as shown in the following code block:
This callback will automatically log the following information into SageMaker Experiments as a part of the training run:
- Training Parameters and Hyper-Parameters
- Model Training and Validation loss at Step, Epoch and Final
- Model Input and Output artifacts (training dataset, validation dataset, model output location, training debugger and more)
The following graph shows examples of the charts you can display by using that information.

This allows you to compare multiple runs easily using the Analyze feature of SageMaker Experiments. You can select the experiment runs you want to compare, and they will automatically populate comparison graphs.

Register fine-tuned models to Model Registry Collections
Model Registry Collections is a feature of SageMaker Model Registry that allows you to group registered models that are related to each other and organize them in hierarchies to improve model discoverability at scale. We will use Model Registry Collections to keep track of the base model and fine-tuned variants.
Full Model Copy method
The first method combines the base model and LoRA adapter and saves the full fine-tuned model. The following code illustrates the model merging process and saves the combined model using model.save_pretrained().
Combining the LoRA adapter and base model into a single model artifact after fine-tuning has advantages and disadvantages. The combined model is self-contained and can be independently managed and deployed without needing the original base model. The model can be tracked as its own entity with a version name reflecting the base model and fine-tuning data. We can adopt a nomenclature using the base_model_name + fine-tuned dataset_name to organize the model groups. Optionally, model collections could associate the original and fine-tuned models, but this may not be necessary since the combined model is independent. The following code snippet shows you how to register the fine-tuned model.
You can use the training estimator to register the model into Model Registry.
From Model Registry, you can retrieve the model package and deploy that model directly.
However, there are drawbacks to this approach. Combining the models leads to storage inefficiency and redundancy since the base model is duplicated in each fine-tuned version. As model size and the number of fine-tuned models increase, this exponentially inflates storage needs. Taking the llama2 7b model as an example, the base model is approximately 13 GB and the fine-tuned model is 13.6 GB. 96% percent of the model needs to be duplicated after each fine tuning. Additionally, distributing and sharing very large model files also becomes more difficult and presents operational challenges as file transfer and management cost increases with increasing model size and fine-tune jobs.
Separate adapter and base method
The second method focuses on separation of base weights and adapter weights by saving them as separate model components and loading them sequentially at runtime.
Saving base and adapter weights has advantages and disadvantages, similar to the Full Model Copy method. One advantage is that it can save storage space. The base weights, which are the largest component of a fine-tuned model, are only saved once and can be reused with other adapter weights that are tuned for different tasks. For example, the base weights of Llama2-7B are about 13 GB, but each fine-tuning task only needs to store about 0.6 GB of adapter weights, which is a 95% space savings. Another advantage is that base weights can be managed separately from adapter weights using a base weights only model registry. This can be useful for SageMaker domains that are running in a VPC only mode without an internet gateway, since the base weights can be accessed without having to go through the internet.
Create Model Package Group for base weights
Create Model Package Group for QLoRA weights
The following code shows how to tag QLoRA weights with the dataset/task type and register fine-tuned delta weights into a separate model registry and track the delta weights separately.
The following snippet shows a view from the Model Registry where the models are split into base and fine-tuned weights.

Managing models, datasets, and tasks for hyper-personalized LLMs can quickly become overwhelming. SageMaker Model Registry Collections can help you group related models together and organize them in a hierarchy to improve model discoverability. This makes it easier to track the relationships between base weights, adapter weights, and fine-tuning task datasets. You can also create complex relationships and linkages between models.
Create a new Collection and add your base model weights to this Collection
Link all your Fine-Tuned LoRA Adapter Delta Weights to this collection by task and/or dataset
This will result in a collection hierarchy which are linked by model/task type and the dataset used to fine tune the base model.

This method of separating the base and adapter models has some drawbacks. One drawback is complexity in deploying the model. Because there are two separate model artifacts, you need additional steps to repackage the model instead of deploy directly from Model Registry. In the following code example, download and repack the latest version of the base model first.
Then download and repack the latest fine-tuned LoRA adapter weights.
Since you will be using DJL serving with deepspeed to host the model, your inference directory should look like the following.
Finally, package the custom inference code, base model, and LoRA adaptor in a single .tar.gz file for deployment.
Clean up
Clean up your resources by following the instructions in the cleanup section of the notebook. Refer to Amazon SageMaker Pricing for details on the cost of the inference instances.
Conclusion
This post walked you through best practices for managing LoRA fine-tuned models on Amazon SageMaker. We covered two main methods: combining the base and adapter weights into one self-contained model, and separating the base and adapter weights. Both approaches have tradeoffs, but separating weights helps optimize storage and enables advanced model management techniques like SageMaker Model Registry Collections. This allows you to build hierarchies and relationships between models to improve organization and discoverability. We encourage you to try the sample code on GitHub repository to experiment with these methods yourself. As generative AI progresses rapidly, following model management best practices will help you track experiments, find the right model for your task, and manage specialized LLMs efficiently at scale.
References
About the authors
 James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
 Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes. In his free time, he enjoys playing chess and traveling.
Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes. In his free time, he enjoys playing chess and traveling.
 Mecit Gungor is an AI/ML Specialist Solution Architect at AWS helping customers design and build AI/ML solutions at scale. He covers a wide range of AI/ML use cases for Telecommunication customers and currently focuses on Generative AI, LLMs, and training and inference optimization. He can often be found hiking in the wilderness or playing board games with his friends in his free time.
Mecit Gungor is an AI/ML Specialist Solution Architect at AWS helping customers design and build AI/ML solutions at scale. He covers a wide range of AI/ML use cases for Telecommunication customers and currently focuses on Generative AI, LLMs, and training and inference optimization. He can often be found hiking in the wilderness or playing board games with his friends in his free time.
 Shelbee Eigenbrode is a Principal AI and Machine Learning Specialist Solutions Architect at Amazon Web Services (AWS). She has been in technology for 24 years spanning multiple industries, technologies, and roles. She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera. She is also the Co-Director of Women In Big Data (WiBD), Denver chapter. In her spare time, she likes to spend time with her family, friends, and overactive dogs.
Shelbee Eigenbrode is a Principal AI and Machine Learning Specialist Solutions Architect at Amazon Web Services (AWS). She has been in technology for 24 years spanning multiple industries, technologies, and roles. She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera. She is also the Co-Director of Women In Big Data (WiBD), Denver chapter. In her spare time, she likes to spend time with her family, friends, and overactive dogs.