
Amazon SageMaker is an end-to-end machine learning (ML) platform with wide-ranging features to ingest, transform, and measure bias in data, and train, deploy, and manage models in production with best-in-class compute and services such as Amazon SageMaker Data Wrangler, Amazon SageMaker Studio, Amazon SageMaker Canvas, Amazon SageMaker Model Registry, Amazon SageMaker Feature Store, Amazon SageMaker Pipelines, Amazon SageMaker Model Monitor, and Amazon SageMaker Clarify. Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and data scientists. A number of AWS independent software vendor (ISV) partners have already built integrations for users of their software as a service (SaaS) platforms to utilize SageMaker and its various features, including training, deployment, and the model registry.
In this post, we cover the benefits for SaaS platforms to integrate with SageMaker, the range of possible integrations, and the process for developing these integrations. We also deep dive into the most common architectures and AWS resources to facilitate these integrations. This is intended to accelerate time-to-market for ISV partners and other SaaS providers building similar integrations and inspire customers who are users of SaaS platforms to partner with SaaS providers on these integrations.
Benefits of integrating with SageMaker
There are a number of benefits for SaaS providers to integrate their SaaS platforms with SageMaker:
- Users of the SaaS platform can take advantage of a comprehensive ML platform in SageMaker
- Users can build ML models with data that is in or outside of the SaaS platform and exploit these ML models
- It provides users with a seamless experience between the SaaS platform and SageMaker
- Users can utilize foundation models available in Amazon SageMaker JumpStart to build generative AI applications
- Organizations can standardize on SageMaker
- SaaS providers can focus on their core functionality and offer SageMaker for ML model development
- It equips SaaS providers with a basis to build joint solutions and go to market with AWS
SageMaker overview and integration options
SageMaker has tools for every step of the ML lifecycle. SaaS platforms can integrate with SageMaker across the ML lifecycle from data labeling and preparation to model training, hosting, monitoring, and managing models with various components, as shown in the following figure. Depending on the needs, any and all parts of the ML lifecycle can be run in either the customer AWS account or SaaS AWS account, and data and models can be shared across accounts using AWS Identity and Access Management (IAM) policies or third-party user-based access tools. This flexibility in the integration makes SageMaker an ideal platform for customers and SaaS providers to standardize on.
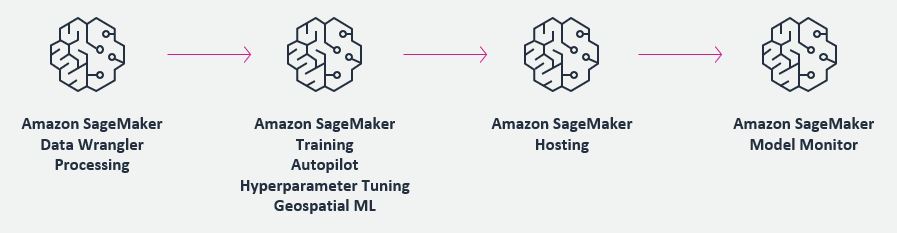
Integration process and architectures
In this section, we break the integration process into four main stages and cover the common architectures. Note that there can be other integration points in addition to these, but those are less common.
- Data access – How data that is in the SaaS platform is accessed from SageMaker
- Model training – How the model is trained
- Model deployment and artifacts – Where the model is deployed and what artifacts are produced
- Model inference – How the inference happens in the SaaS platform
The diagrams in the following sections assume SageMaker is running in the customer AWS account. Most of the options explained are also applicable if SageMaker is running in the SaaS AWS account. In some cases, an ISV may deploy their software in the customer AWS account. This is usually in a dedicated customer AWS account, meaning there still needs to be cross-account access to the customer AWS account where SageMaker is running.
There are a few different ways in which authentication across AWS accounts can be achieved when data in the SaaS platform is accessed from SageMaker and when the ML model is invoked from the SaaS platform. The recommended method is to use IAM roles. An alternative is to use AWS access keys consisting of an access key ID and secret access key.
Data access
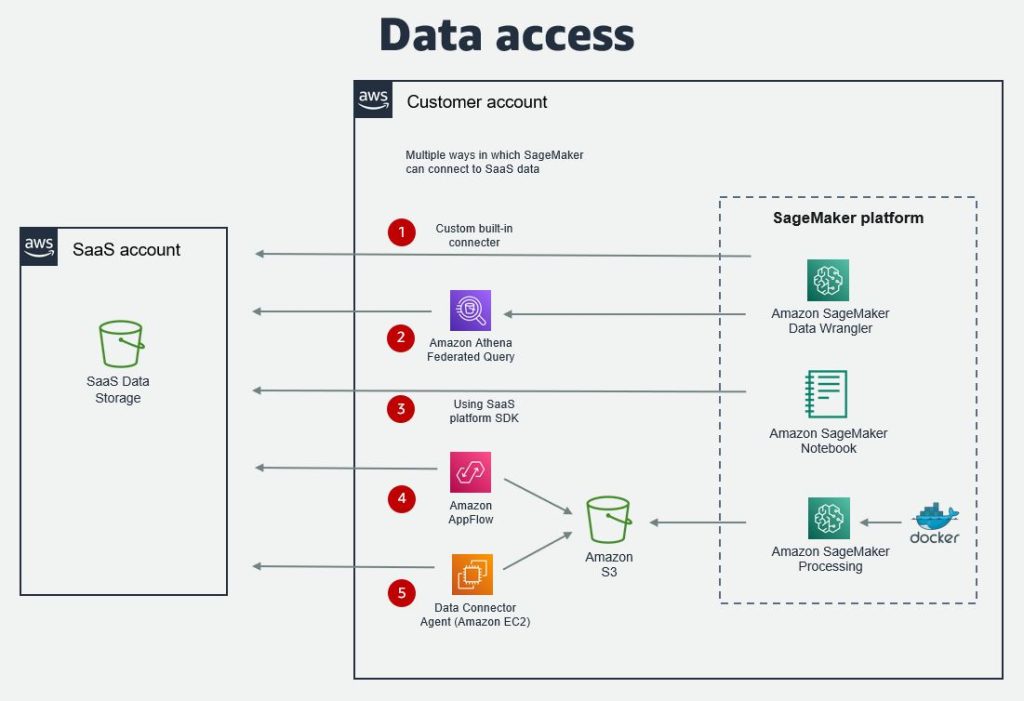
There are multiple options on how data that is in the SaaS platform can be accessed from SageMaker. Data can either be accessed from a SageMaker notebook, SageMaker Data Wrangler, where users can prepare data for ML, or SageMaker Canvas. The most common data access options are:
- SageMaker Data Wrangler built-in connector – The SageMaker Data Wrangler connector enables data to be imported from a SaaS platform to be prepared for ML model training. The connector is developed jointly by AWS and the SaaS provider. Current SaaS platform connectors include Databricks and Snowflake.
- Amazon Athena Federated Query for the SaaS platform – Federated queries enable users to query the platform from a SageMaker notebook via Amazon Athena using a custom connector that is developed by the SaaS provider.
- Amazon AppFlow – With Amazon AppFlow, you can use a custom connector to extract data into Amazon Simple Storage Service (Amazon S3) which subsequently can be accessed from SageMaker. The connector for a SaaS platform can be developed by AWS or the SaaS provider. The open-source Custom Connector SDK enables the development of a private, shared, or public connector using Python or Java.
- SaaS platform SDK – If the SaaS platform has an SDK (Software Development Kit), such as a Python SDK, this can be used to access data directly from a SageMaker notebook.
- Other options – In addition to these, there can be other options depending on whether the SaaS provider exposes their data via APIs, files or an agent. The agent can be installed on Amazon Elastic Compute Cloud (Amazon EC2) or AWS Lambda. Alternatively, a service such as AWS Glue or a third-party extract, transform, and load (ETL) tool can be used for data transfer.
The following diagram illustrates the architecture for data access options.
Model training
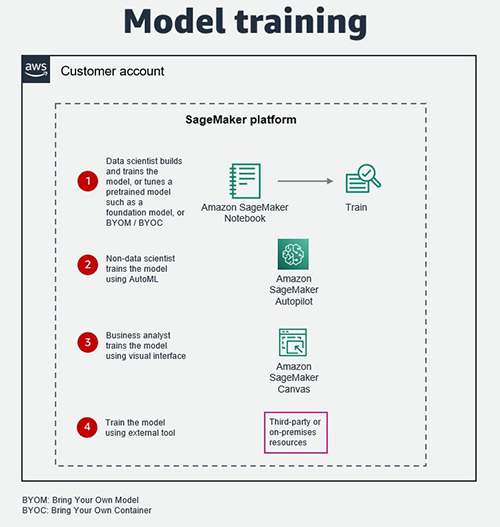
The model can be trained in SageMaker Studio by a data scientist, using Amazon SageMaker Autopilot by a non-data scientist, or in SageMaker Canvas by a business analyst. SageMaker Autopilot takes away the heavy lifting of building ML models, including feature engineering, algorithm selection, and hyperparameter settings, and it is also relatively straightforward to integrate directly into a SaaS platform. SageMaker Canvas provides a no-code visual interface for training ML models.
In addition, Data scientists can use pre-trained models available in SageMaker JumpStart, including foundation models from sources such as Alexa, AI21 Labs, Hugging Face, and Stability AI, and tune them for their own generative AI use cases.
Alternatively, the model can be trained in a third-party or partner-provided tool, service, and infrastructure, including on-premises resources, provided the model artifacts are accessible and readable.
The following diagram illustrates these options.
Model deployment and artifacts
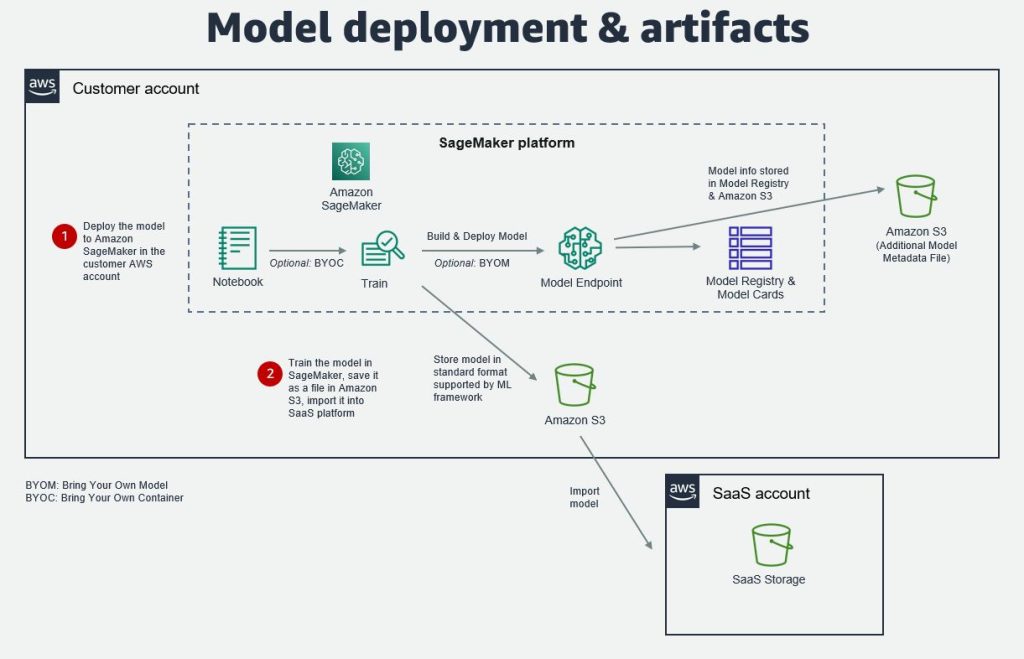
After you have trained and tested the model, you can either deploy it to a SageMaker model endpoint in the customer account, or export it from SageMaker and import it into the SaaS platform storage. The model can be stored and imported in standard formats supported by the common ML frameworks, such as pickle, joblib, and ONNX (Open Neural Network Exchange).
If the ML model is deployed to a SageMaker model endpoint, additional model metadata can be stored in the SageMaker Model Registry, SageMaker Model Cards, or in a file in an S3 bucket. This can be the model version, model inputs and outputs, model metrics, model creation date, inference specification, data lineage information, and more. Where there isn’t a property available in the model package, the data can be stored as custom metadata or in an S3 file.
Creating such metadata can help SaaS providers manage the end-to-end lifecycle of the ML model more effectively. This information can be synced to the model log in the SaaS platform and used to track changes and updates to the ML model. Subsequently, this log can be used to determine whether to refresh downstream data and applications that use that ML model in the SaaS platform.
The following diagram illustrates this architecture.
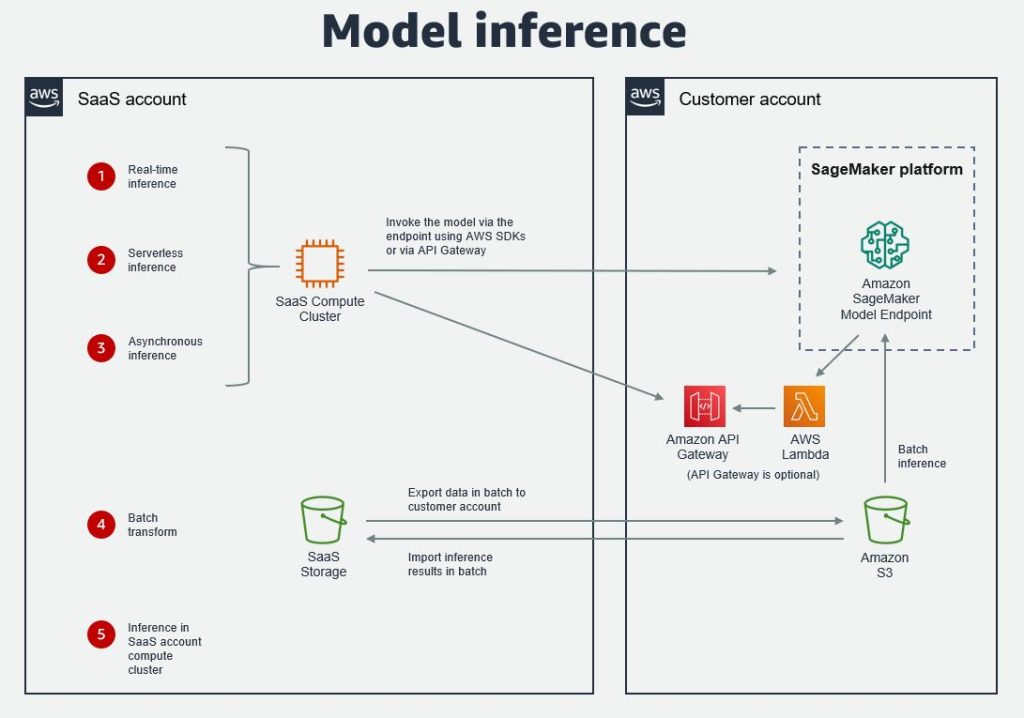
Model inference
SageMaker offers four options for ML model inference: real-time inference, serverless inference, asynchronous inference, and batch transform. For the first three, the model is deployed to a SageMaker model endpoint and the SaaS platform invokes the model using the AWS SDKs. The recommended option is to use the Python SDK. The inference pattern for each of these is similar in that the predictor’s predict() or predict_async() methods are used. Cross-account access can be achieved using role-based access.
It’s also possible to seal the backend with Amazon API Gateway, which calls the endpoint via a Lambda function that runs in a protected private network.
For batch transform, data from the SaaS platform first needs to be exported in batch into an S3 bucket in the customer AWS account, then the inference is done on this data in batch. The inference is done by first creating a transformer job or object, and then calling the transform() method with the S3 location of the data. Results are imported back into the SaaS platform in batch as a dataset, and joined to other datasets in the platform as part of a batch pipeline job.
Another option for inference is to do it directly in the SaaS account compute cluster. This would be the case when the model has been imported into the SaaS platform. In this case, SaaS providers can choose from a range of EC2 instances that are optimized for ML inference.
The following diagram illustrates these options.
Example integrations
Several ISVs have built integrations between their SaaS platforms and SageMaker. To learn more about some example integrations, refer to the following:
- Enabling Data-Centric Artificial Intelligence Through Snowflake and Amazon SageMaker
- Machine Learning for Everyone with Amazon SageMaker Autopilot and Domo
- How to architect end-to-end development, monitoring, and maintenance of your models in AWS and Domino Data Lab
Conclusion
In this post, we explained why and how SaaS providers should integrate SageMaker with their SaaS platforms by breaking the process into four parts and covering the common integration architectures. SaaS providers looking to build an integration with SageMaker can utilize these architectures. If there are any custom requirements beyond what has been covered in this post, including with other SageMaker components, get in touch with your AWS account teams. Once the integration has been built and validated, ISV partners can join the AWS Service Ready Program for SageMaker and unlock a variety of benefits.
We also ask customers who are users of SaaS platforms to register their interest in an integration with Amazon SageMaker with their AWS account teams, as this can help inspire and progress the development for SaaS providers.
About the Authors
![]() Mehmet Bakkaloglu is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML and ISV partners.
Mehmet Bakkaloglu is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML and ISV partners.
![]() Raj Kadiyala is a Principal AI/ML Evangelist at AWS.
Raj Kadiyala is a Principal AI/ML Evangelist at AWS.