This blog is co-written with Josh Reini, Shayak Sen and Anupam Datta from TruEra
Amazon SageMaker JumpStart provides a variety of pretrained foundation models such as Llama-2 and Mistal 7B that can be quickly deployed to an endpoint. These foundation models perform well with generative tasks, from crafting text and summaries, answering questions, to producing images and videos. Despite the great generalization capabilities of these models, there are often use cases where these models have to be adapted to new tasks or domains. One way to surface this need is by evaluating the model against a curated ground truth dataset. After the need to adapt the foundation model is clear, you can use a set of techniques to carry that out. A popular approach is to fine-tune the model using a dataset that is tailored to the use case. Fine-tuning can improve the foundation model and its efficacy can again be measured against the ground truth dataset. This notebook shows how to fine-tune models with SageMaker JumpStart.
One challenge with this approach is that curated ground truth datasets are expensive to create. In this post, we address this challenge by augmenting this workflow with a framework for extensible, automated evaluations. We start off with a baseline foundation model from SageMaker JumpStart and evaluate it with TruLens, an open source library for evaluating and tracking large language model (LLM) apps. After we identify the need for adaptation, we can use fine-tuning in SageMaker JumpStart and confirm improvement with TruLens.

TruLens evaluations use an abstraction of feedback functions. These functions can be implemented in several ways, including BERT-style models, appropriately prompted LLMs, and more. TruLens’ integration with Amazon Bedrock allows you to run evaluations using LLMs available from Amazon Bedrock. The reliability of the Amazon Bedrock infrastructure is particularly valuable for use in performing evaluations across development and production.
This post serves as both an introduction to TruEra’s place in the modern LLM app stack and a hands-on guide to using Amazon SageMaker and TruEra to deploy, fine-tune, and iterate on LLM apps. Here is the complete notebook with code samples to show performance evaluation using TruLens
TruEra in the LLM app stack
TruEra lives at the observability layer of LLM apps. Although new components have worked their way into the compute layer (fine-tuning, prompt engineering, model APIs) and storage layer (vector databases), the need for observability remains. This need spans from development to production and requires interconnected capabilities for testing, debugging, and production monitoring, as illustrated in the following figure.
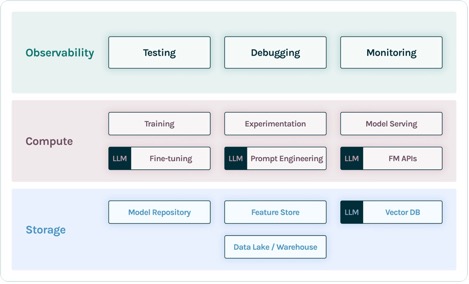
In development, you can use open source TruLens to quickly evaluate, debug, and iterate on your LLM apps in your environment. A comprehensive suite of evaluation metrics, including both LLM-based and traditional metrics available in TruLens, allows you to measure your app against criteria required for moving your application to production.
In production, these logs and evaluation metrics can be processed at scale with TruEra production monitoring. By connecting production monitoring with testing and debugging, dips in performance such as hallucination, safety, security, and more can be identified and corrected.
Deploy foundation models in SageMaker
You can deploy foundation models such as Llama-2 in SageMaker with just two lines of Python code:
Invoke the model endpoint
After deployment, you can invoke the deployed model endpoint by first creating a payload containing your inputs and model parameters:
Then you can simply pass this payload to the endpoint’s predict method. Note that you must pass the attribute to accept the end-user license agreement each time you invoke the model:
Evaluate performance with TruLens
Now you can use TruLens to set up your evaluation. TruLens is an observability tool, offering an extensible set of feedback functions to track and evaluate LLM-powered apps. Feedback functions are essential here in verifying the absence of hallucination in the app. These feedback functions are implemented by using off-the-shelf models from providers such as Amazon Bedrock. Amazon Bedrock models are an advantage here because of their verified quality and reliability. You can set up the provider with TruLens via the following code:
In this example, we use three feedback functions: answer relevance, context relevance, and groundedness. These evaluations have quickly become the standard for hallucination detection in context-enabled question answering applications and are especially useful for unsupervised applications, which cover the vast majority of today’s LLM applications.
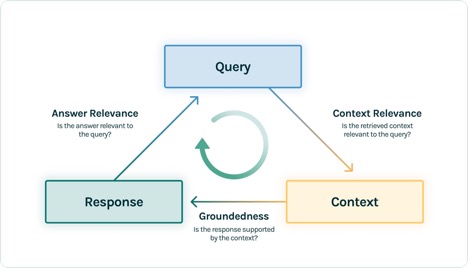
Let’s go through each of these feedback functions to understand how they can benefit us.
Context relevance
Context is a critical input to the quality of our application’s responses, and it can be useful to programmatically ensure that the context provided is relevant to the input query. This is critical because this context will be used by the LLM to form an answer, so any irrelevant information in the context could be weaved into a hallucination. TruLens enables you to evaluate context relevance by using the structure of the serialized record:
Because the context provided to LLMs is the most consequential step of a Retrieval Augmented Generation (RAG) pipeline, context relevance is critical for understanding the quality of retrievals. Working with customers across sectors, we’ve seen a variety of failure modes identified using this evaluation, such as incomplete context, extraneous irrelevant context, or even lack of sufficient context available. By identifying the nature of these failure modes, our users are able to adapt their indexing (such as embedding model and chunking) and retrieval strategies (such as sentence windowing and automerging) to mitigate these issues.
Groundedness
After the context is retrieved, it is then formed into an answer by an LLM. LLMs are often prone to stray from the facts provided, exaggerating or expanding to a correct-sounding answer. To verify the groundedness of the application, you should separate the response into separate statements and independently search for evidence that supports each within the retrieved context.
Issues with groundedness can often be a downstream effect of context relevance. When the LLM lacks sufficient context to form an evidence-based response, it is more likely to hallucinate in its attempt to generate a plausible response. Even in cases where complete and relevant context is provided, the LLM can fall into issues with groundedness. Particularly, this has played out in applications where the LLM responds in a particular style or is being used to complete a task it is not well suited for. Groundedness evaluations allow TruLens users to break down LLM responses claim by claim to understand where the LLM is most often hallucinating. Doing so has shown to be particularly useful for illuminating the way forward in eliminating hallucination through model-side changes (such as prompting, model choice, and model parameters).
Answer relevance
Lastly, the response still needs to helpfully answer the original question. You can verify this by evaluating the relevance of the final response to the user input:
By reaching satisfactory evaluations for this triad, you can make a nuanced statement about your application’s correctness; this application is verified to be hallucination free up to the limit of its knowledge base. In other words, if the vector database contains only accurate information, then the answers provided by the context-enabled question answering app are also accurate.
Ground truth evaluation
In addition to these feedback functions for detecting hallucination, we have a test dataset, DataBricks-Dolly-15k, that enables us to add ground truth similarity as a fourth evaluation metric. See the following code:
Build the application
After you have set up your evaluators, you can build your application. In this example, we use a context-enabled QA application. In this application, provide the instruction and context to the completion engine:
After you have created the app and feedback functions, it’s straightforward to create a wrapped application with TruLens. This wrapped application, which we name base_recorder, will log and evaluate the application each time it is called:
Results with base Llama-2
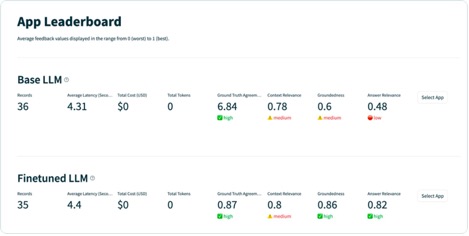
After you have run the application on each record in the test dataset, you can view the results in your SageMaker notebook with tru.get_leaderboard(). The following screenshot shows the results of the evaluation. Answer relevance is alarmingly low, indicating that the model is struggling to consistently follow the instructions provided.

Fine-tune Llama-2 using SageMaker Jumpstart
Steps to fine tune Llama-2 model using SageMaker Jumpstart are also provided in this notebook.
To set up for fine-tuning, you first need to download the training set and setup a template for instructions
Then, upload both the dataset and instructions to an Amazon Simple Storage Service (Amazon S3) bucket for training:
To fine-tune in SageMaker, you can use the SageMaker JumpStart Estimator. We mostly use default hyperparameters here, except we set instruction tuning to true:
After you have trained the model, you can deploy it and create your application just as you did before:
Evaluate the fine-tuned model
You can run the model again on your test set and view the results, this time in comparison to the base Llama-2:

The new, fine-tuned Llama-2 model has massively improved on answer relevance and groundedness, along with similarity to the ground truth test set. This large improvement in quality comes at the expense of a slight increase in latency. This increase in latency is a direct result of the fine-tuning increasing the size of the model.
Not only can you view these results in the notebook, but you can also explore the results in the TruLens UI by running tru.run_dashboard(). Doing so can provide the same aggregated results on the leaderboard page, but also gives you the ability to dive deeper into problematic records and identify failure modes of the application.
To understand the improvement to the app on a record level, you can move to the evaluations page and examine the feedback scores on a more granular level.
For example, if you ask the base LLM the question “What is the most powerful Porsche flat six engine,” the model hallucinates the following.

Additionally, you can examine the programmatic evaluation of this record to understand the application’s performance against each of the feedback functions you have defined. By examining the groundedness feedback results in TruLens, you can see a detailed breakdown of the evidence available to support each claim being made by the LLM.

If you export the same record for your fine-tuned LLM in TruLens, you can see that fine-tuning with SageMaker JumpStart dramatically improved the groundedness of the response.

By using an automated evaluation workflow with TruLens, you can measure your application across a wider set of metrics to better understand its performance. Importantly, you are now able to understand this performance dynamically for any use case—even those where you have not collected ground truth.
How TruLens works
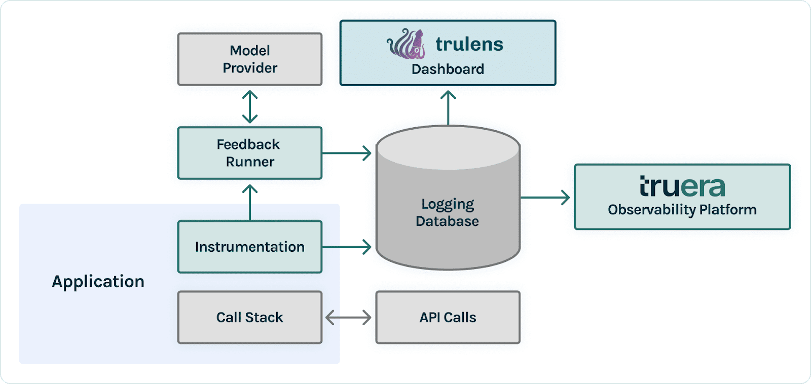
After you have prototyped your LLM application, you can integrate TruLens (shown earlier) to instrument its call stack. After the call stack is instrumented, it can then be logged on each run to a logging database living in your environment.
In addition to the instrumentation and logging capabilities, evaluation is a core component of value for TruLens users. These evaluations are implemented in TruLens by feedback functions to run on top of your instrumented call stack, and in turn call upon external model providers to produce the feedback itself.
After feedback inference, the feedback results are written to the logging database, from which you can run the TruLens dashboard. The TruLens dashboard, running in your environment, allows you to explore, iterate, and debug your LLM app.
At scale, these logs and evaluations can be pushed to TruEra for production observability that can process millions of observations a minute. By using the TruEra Observability Platform, you can rapidly detect hallucination and other performance issues, and zoom in to a single record in seconds with integrated diagnostics. Moving to a diagnostics viewpoint allows you to easily identify and mitigate failure modes for your LLM app such as hallucination, poor retrieval quality, safety issues, and more.
Evaluate for honest, harmless, and helpful responses
By reaching satisfactory evaluations for this triad, you can reach a higher degree of confidence in the truthfulness of responses it provides. Beyond truthfulness, TruLens has broad support for the evaluations needed to understand your LLM’s performance on the axis of “Honest, Harmless, and Helpful.” Our users have benefited tremendously from the ability to identify not only hallucination as we discussed earlier, but also issues with safety, security, language match, coherence, and more. These are all messy, real-world problems that LLM app developers face, and can be identified out of the box with TruLens.

Conclusion
This post discussed how you can accelerate the productionisation of AI applications and use foundation models in your organization. With SageMaker JumpStart, Amazon Bedrock, and TruEra, you can deploy, fine-tune, and iterate on foundation models for your LLM application. Checkout this link to find out more about TruEra and try the notebook yourself.
About the authors
 Josh Reini is a core contributor to open-source TruLens and the founding Developer Relations Data Scientist at TruEra where he is responsible for education initiatives and nurturing a thriving community of AI Quality practitioners.
Josh Reini is a core contributor to open-source TruLens and the founding Developer Relations Data Scientist at TruEra where he is responsible for education initiatives and nurturing a thriving community of AI Quality practitioners.
 Shayak Sen is the CTO & Co-Founder of TruEra. Shayak is focused on building systems and leading research to make machine learning systems more explainable, privacy compliant, and fair.
Shayak Sen is the CTO & Co-Founder of TruEra. Shayak is focused on building systems and leading research to make machine learning systems more explainable, privacy compliant, and fair.
 Anupam Datta is Co-Founder, President, and Chief Scientist of TruEra. Before TruEra, he spent 15 years on the faculty at Carnegie Mellon University (2007-22), most recently as a tenured Professor of Electrical & Computer Engineering and Computer Science.
Anupam Datta is Co-Founder, President, and Chief Scientist of TruEra. Before TruEra, he spent 15 years on the faculty at Carnegie Mellon University (2007-22), most recently as a tenured Professor of Electrical & Computer Engineering and Computer Science.
![]() Vivek Gangasani is a AI/ML Startup Solutions Architect for Generative AI startups at AWS. He helps emerging GenAI startups build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
Vivek Gangasani is a AI/ML Startup Solutions Architect for Generative AI startups at AWS. He helps emerging GenAI startups build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.