
Reflecting on ChatGPT's first year, it's clear that this tool has significantly changed the AI scene. Launched at the end of 2022, ChatGPT stood out because of its user-friendly, conversational style that made interacting with AI feel more like chatting with a person than a machine. This new approach quickly caught the public's eye. Within just five days after its release, ChatGPT had already attracted a million users. By early 2023, this number ballooned to about 100 million monthly users, and by October, the platform was drawing in around 1.7 billion visits worldwide. These numbers speak volumes about its popularity and usefulness.
Over the past year, users have found all sorts of creative ways to use ChatGPT, from simple tasks like writing emails and updating resumes to starting successful businesses. But it's not just about how people are using it; the technology itself has grown and improved. Initially, ChatGPT was a free service offering detailed text responses. Now, there's ChatGPT Plus, which includes ChatGPT-4. This updated version is trained on more data, gives fewer wrong answers, and understands complex instructions better.
One of the biggest updates is that ChatGPT can now interact in multiple ways – it can listen, speak, and even process images. This means you can talk to it through its mobile app and show it pictures to get responses. These changes have opened up new possibilities for AI and have changed how people view and think about AI's role in our lives.
From its beginnings as a tech demo to its current status as a major player in the tech world, ChatGPT's journey is quite impressive. Initially, it was seen as a way to test and improve technology by getting feedback from the public. But it quickly became an essential part of the AI landscape. This success shows how effective it is to fine-tune large language models (LLMs) with both supervised learning and feedback from humans. As a result, ChatGPT can handle a wide range of questions and tasks.
The race to develop the most capable and versatile AI systems has led to a proliferation of both open-source and proprietary models like ChatGPT. Understanding their general capabilities requires comprehensive benchmarks across a wide spectrum of tasks. This section explores these benchmarks, shedding light on how different models, including ChatGPT, stack up against each other.
Evaluating LLMs: The Benchmarks
- MT-Bench: This benchmark tests multi-turn conversation and instruction-following abilities across eight domains: writing, roleplay, information extraction, reasoning, math, coding, STEM knowledge, and humanities/social sciences. Stronger LLMs like GPT-4 are used as evaluators.
- AlpacaEval: Based on the AlpacaFarm evaluation set, this LLM-based automatic evaluator benchmarks models against responses from advanced LLMs like GPT-4 and Claude, calculating the win rate of candidate models.
- Open LLM Leaderboard: Utilizing the Language Model Evaluation Harness, this leaderboard evaluates LLMs on seven key benchmarks, including reasoning challenges and general knowledge tests, in both zero-shot and few-shot settings.
- BIG-bench: This collaborative benchmark covers over 200 novel language tasks, spanning a diverse range of topics and languages. It aims to probe LLMs and predict their future capabilities.
- ChatEval: A multi-agent debate framework that allows teams to autonomously discuss and evaluate the quality of responses from different models on open-ended questions and traditional natural language generation tasks.
Comparative Performance
In terms of general benchmarks, open-source LLMs have shown remarkable progress. Llama-2-70B, for instance, achieved impressive results, particularly after being fine-tuned with instruction data. Its variant, Llama-2-chat-70B, excelled in AlpacaEval with a 92.66% win rate, surpassing GPT-3.5-turbo. However, GPT-4 remains the frontrunner with a 95.28% win rate.
Zephyr-7B, a smaller model, demonstrated capabilities comparable to larger 70B LLMs, especially in AlpacaEval and MT-Bench. Meanwhile, WizardLM-70B, fine-tuned with a diverse range of instruction data, scored the highest among open-source LLMs on MT-Bench. However, it still lagged behind GPT-3.5-turbo and GPT-4.
An interesting entry, GodziLLa2-70B, achieved a competitive score on the Open LLM Leaderboard, showcasing the potential of experimental models combining diverse datasets. Similarly, Yi-34B, developed from scratch, stood out with scores comparable to GPT-3.5-turbo and only slightly behind GPT-4.
UltraLlama, with its fine-tuning on diverse and high-quality data, matched GPT-3.5-turbo in its proposed benchmarks and even surpassed it in areas of world and professional knowledge.
Scaling Up: The Rise of Giant LLMs
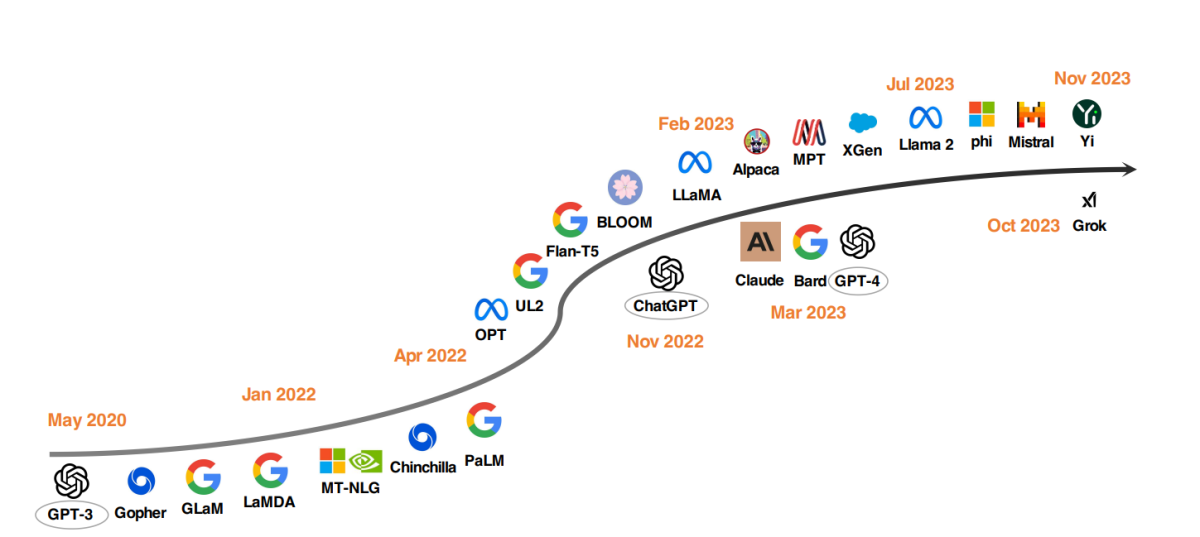
Top LLM models since 2020
A notable trend in LLM development has been the scaling up of model parameters. Models like Gopher, GLaM, LaMDA, MT-NLG, and PaLM have pushed the boundaries, culminating in models with up to 540 billion parameters. These models have shown exceptional capabilities, but their closed-source nature has limited their wider application. This limitation has spurred interest in developing open-source LLMs, a trend that's gaining momentum.
In parallel to scaling up model sizes, researchers have explored alternative strategies. Instead of just making models bigger, they've focused on improving the pre-training of smaller models. Examples include Chinchilla and UL2, which have shown that more isn't always better; smarter strategies can yield efficient results too. Furthermore, there's been considerable attention on instruction tuning of language models, with projects like FLAN, T0, and Flan-T5 making significant contributions to this area.
The ChatGPT Catalyst
The introduction of OpenAI's ChatGPT marked a turning point in NLP research. To compete with OpenAI, companies like Google and Anthropic launched their own models, Bard and Claude, respectively. While these models show comparable performance to ChatGPT in many tasks, they still lag behind the latest model from OpenAI, GPT-4. The success of these models is primarily attributed to reinforcement learning from human feedback (RLHF), a technique that's receiving increased research focus for further improvement.
Rumors and Speculations Around OpenAI's Q* (Q-Star)
Recent reports suggest that researchers at OpenAI may have achieved a significant advancement in AI with the development of a new model called Q* (pronounced Q star). Allegedly, Q* has the capability to perform grade-school-level math, a feat that has sparked discussions among experts about its potential as a milestone towards artificial general intelligence (AGI). While OpenAI has not commented on these reports, the rumored abilities of Q* have generated considerable excitement and speculation on social media and among AI enthusiasts.
The development of Q* is noteworthy because existing language models like ChatGPT and GPT-4, while capable of some mathematical tasks, are not particularly adept at handling them reliably. The challenge lies in the need for AI models to not only recognize patterns, as they currently do through deep learning and transformers, but also to reason and understand abstract concepts. Math, being a benchmark for reasoning, requires the AI to plan and execute multiple steps, demonstrating a deep grasp of abstract concepts. This ability would mark a significant leap in AI capabilities, potentially extending beyond mathematics to other complex tasks.
However, experts caution against overhyping this development. While an AI system that reliably solves math problems would be an impressive achievement, it doesn't necessarily signal the advent of superintelligent AI or AGI. Current AI research, including efforts by OpenAI, has focused on elementary problems, with varying degrees of success in more complex tasks.
The potential applications advancements like Q* are vast, ranging from personalized tutoring to assisting in scientific research and engineering. However, it's also important to manage expectations and recognize the limitations and safety concerns associated with such advancements. The concerns about AI posing existential risks, a foundational worry of OpenAI, remain pertinent, especially as AI systems begin to interface more with the real world.
The Open-Source LLM Movement
To boost open-source LLM research, Meta released the Llama series models, triggering a wave of new developments based on Llama. This includes models fine-tuned with instruction data, such as Alpaca, Vicuna, Lima, and WizardLM. Research is also branching into enhancing agent capabilities, logical reasoning, and long-context modeling within the Llama-based framework.
Furthermore, there's a growing trend of developing powerful LLMs from scratch, with projects like MPT, Falcon, XGen, Phi, Baichuan, Mistral, Grok, and Yi. These efforts reflect a commitment to democratize the capabilities of closed-source LLMs, making advanced AI tools more accessible and efficient.
The Impact of ChatGPT and Open Source Models in Healthcare
We're looking at a future where LLMs assist in clinical note-taking, form-filling for reimbursements, and supporting physicians in diagnosis and treatment planning. This has caught the attention of both tech giants and healthcare institutions.
Microsoft's discussions with Epic, a leading electronic health records software provider, signal the integration of LLMs into healthcare. Initiatives are already in place at UC San Diego Health and Stanford University Medical Center. Similarly, Google's partnerships with Mayo Clinic and Amazon Web Services‘ launch of HealthScribe, an AI clinical documentation service, mark significant strides in this direction.
However, these rapid deployments raise concerns about ceding control of medicine to corporate interests. The proprietary nature of these LLMs makes them difficult to evaluate. Their possible modification or discontinuation for profitability reasons could compromise patient care, privacy, and safety.
The urgent need is for an open and inclusive approach to LLM development in healthcare. Healthcare institutions, researchers, clinicians, and patients must collaborate globally to build open-source LLMs for healthcare. This approach, similar to the Trillion Parameter Consortium, would allow pooling of computational, financial resources, and expertise.
The post ChatGPT’s First Anniversary: Reshaping the Future of AI Interaction appeared first on Unite.AI.