
Yammer is a social networking platform designed for open and dynamic communications and collaborations within organizations. It allows you to build communities of interest, gather ideas and feedback, and keep everyone informed. It’s available via browser or mobile app, and provides a variety of common social networking features such as private and public communities, news feeds, groups of interest, instant messaging, and more. Each of these features create a huge amount of unstructured data collected over time and stored in multiple repositories. Searching through these fragmented repositories provides an enormous challenge to users, which is where Amazon Kendra comes in.
Amazon Kendra is a highly accurate and simple-to-use intelligent search service powered by machine learning (ML). Amazon Kendra offers a suite of data source connectors to simplify the process of ingesting and indexing your content, wherever it resides. Valuable data in organizations is stored in both structured and unstructured repositories. An enterprise search solution should be able to pull together data across several structured and unstructured repositories to index and search on.
We’re excited to announce that you can now use the Amazon Kendra connector for Yammer to search information stored in Yammer. In this post, we show how to index information stored in Yammer and use Amazon Kendra intelligent search to find answers to your questions accurately and quickly. In addition, the ML-powered intelligent search can accurately find information from unstructured documents containing natural language narrative content, for which keyword search isn’t very effective.
Solution overview
With Amazon Kendra, you can configure multiple data sources to provide a central place to index and search across your document repository. For our solution, we demonstrate how to index a Yammer repository using the Amazon Kendra connector for Yammer. The solution consists of the following steps:
- Configure the Yammer app API connector on Azure and get the connection details.
- Create an Amazon Kendra index.
- Create a Yammer data source.
- Run a sample query to get information.
Prerequisites
To try out the Amazon Kendra connector for Yammer, you need the following:
- Microsoft Azure global admin access.
- An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. For more information, see Overview of access management: Permissions and policies.
- Basic knowledge of AWS.
Configure the Yammer app API connector and gather connection details
Before we set up the Yammer data source, we need a few details about your Yammer repository. Let’s
gather those in advance.
- Log in to the Azure portal using your global admin user account and choose Next.

- Enter your password and choose Sign in.

- On the Azure welcome page, choose App registrations.

Alternatively, you can search for “App Registrations” in the search bar.
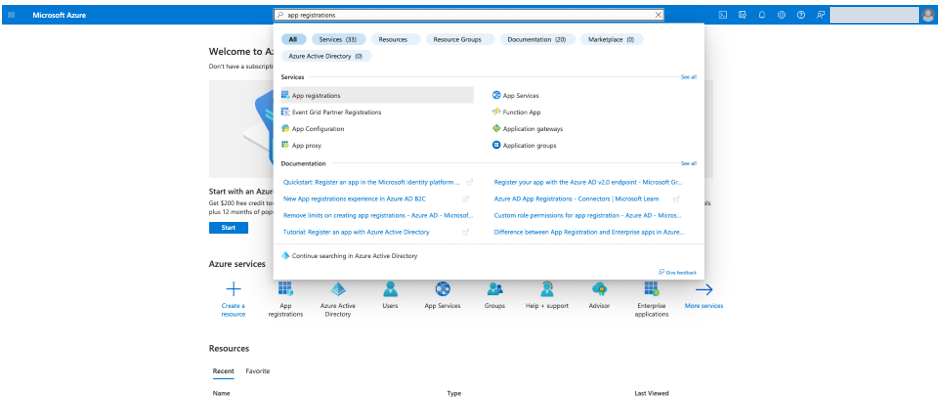
- Choose New registration.

- Enter a name for the app (for example,
my-yammer-connector) and choose Register.

- Note down the tenant ID (you need it when setting up the data source for Amazon Kendra).
- Next to Client credentials, choose Add a certificate or secret.

- Enter a description (for example,
Yammer Connector Client Credentials). - Choose an expiration period (for this post, 6 months).
- Choose Add.

- Save the client ID and secret ID for AWS Secrets Manager configuration.

- In the navigation pane, choose API permissions.

This is where you can add or remove admin permissions.
- Choose Add a permission and choose Yammer for Request API permissions.

- Choose Delegated permissions and select
user_impersonation. - Choose Add permissions.

Now the Yammer connector application is configured in the Azure portal. Let’s switch over to the Amazon Kendra console to complete our setup.
Create an Amazon Kendra index
You can create an Amazon Kendra index or use an existing index. For this post, we create a new index called my-yammer-index. For instructions, refer to Creating an index.
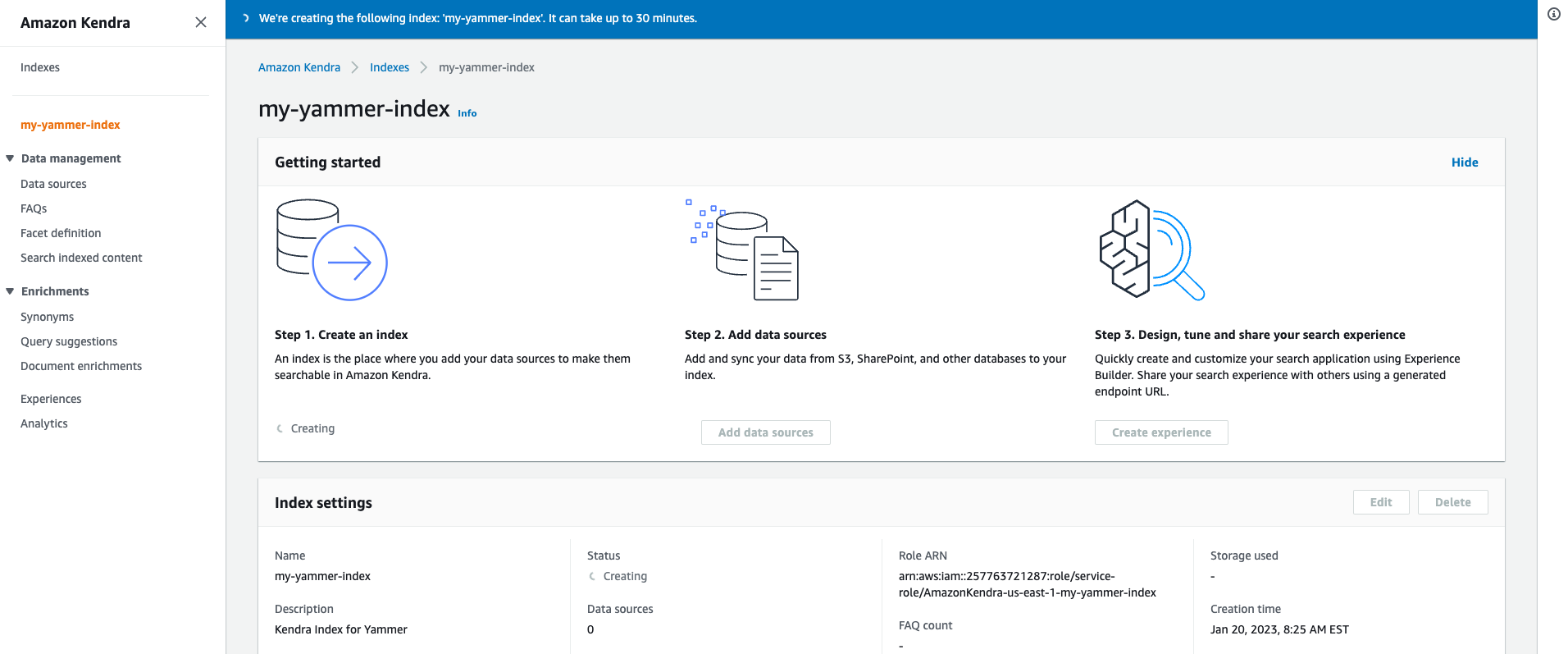
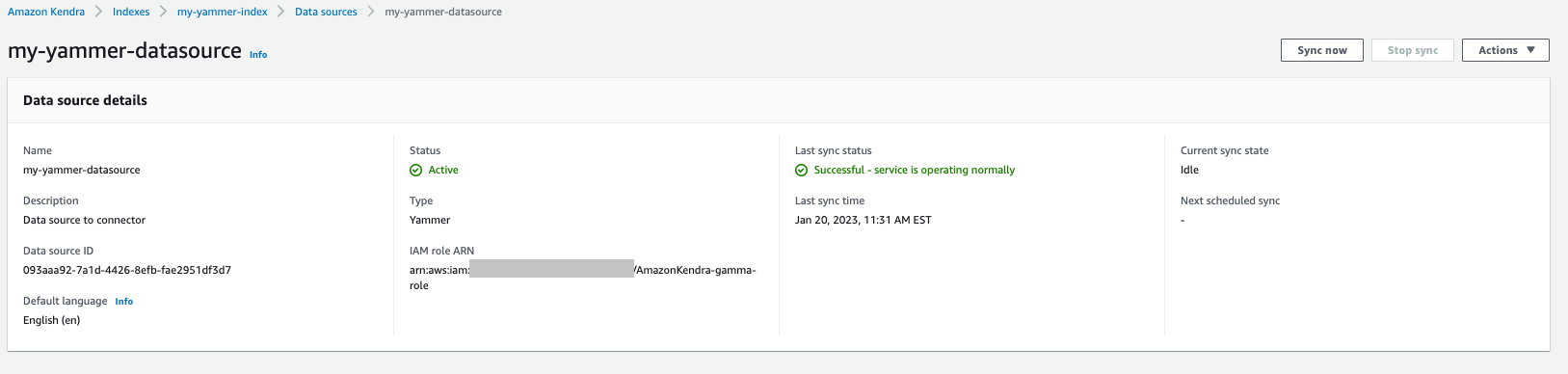
Create a Yammer data source
Complete the following steps to create your data source:
- On the Amazon Kendra console, choose Data sources in the navigation pane.
- Under Microsoft Yammer connector, choose Add connector.

- For Data source name, enter a name (for example,
my-yammer-datasource). - Enter an optional description.
- Choose Next.

You have the choice of creating credentials in Secrets Manager in advance. For this post, we create a secret on-demand.
- Configure a Secrets Manager secret with the user name, password, client ID, and secret ID you collected earlier.
- Choose Save.

- For IAM role, choose Create a new role.
- For Role name, choose
AmazonKendra-my-yammer-iam-role. - Choose Next.

- In the Configure sync settings section, you can optionally configure contents to sync, communities to include, and date since.

- Choose Sync mode and Sync run schedule.
You can choose how you want to update your index when your data source content changes. Amazon Kendra provides three types of sync modes:
- Full sync – Amazon Kendra will sync all contents in all entities, regardless of the previous sync status
- New or modified content sync – Amazon Kendra will only sync new or modified content
- New, modified, or deleted content sync – Amazon Kendra will only sync new, modified, or deleted content
- For this post, select Full sync.
- For Frequency, choose Run on demand
- Choose Next.

- You can optionally set field mappings and Amazon Kendra associates data fields with the index.

- Choose Next.

- Review and choose Add data source.

- Choose Sync now.
The sync takes between minutes to hours based on the size of the repository Amazon Kendra is indexing.
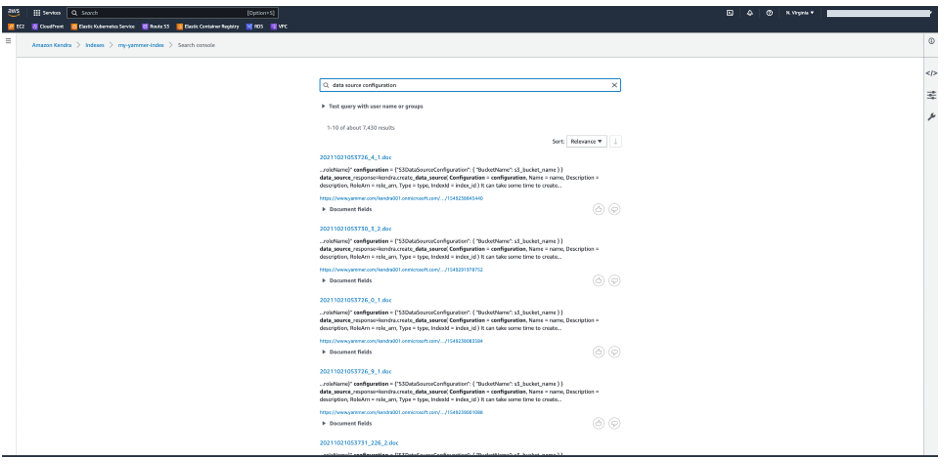
Test the solution
Now that you have ingested the content from Yammer into your Amazon Kendra index, you can test some queries.
- On the Amazon Kendra console, navigate to your index and choose Search indexed content.
- Enter a sample search query and test out your search results (your query will vary based on the contents of your account).
The Yammer connector also crawls local identity information from Yammer. When a document is indexed into Amazon Kendra, a corresponding Access Control List (ACL) is ingested for most documents.
The ACL specifies which user names and group names are allowed or denied access to the document. Documents without an ACL are public documents. You can use this feature to narrow down your query by user.
You can use the user ID (email) to filter search results based on the user or their group access to documents. When you issue a query, Amazon Kendra checks the user and group information and runs the query. All the documents relevant to the query that the user has access to, including public documents, are returned.
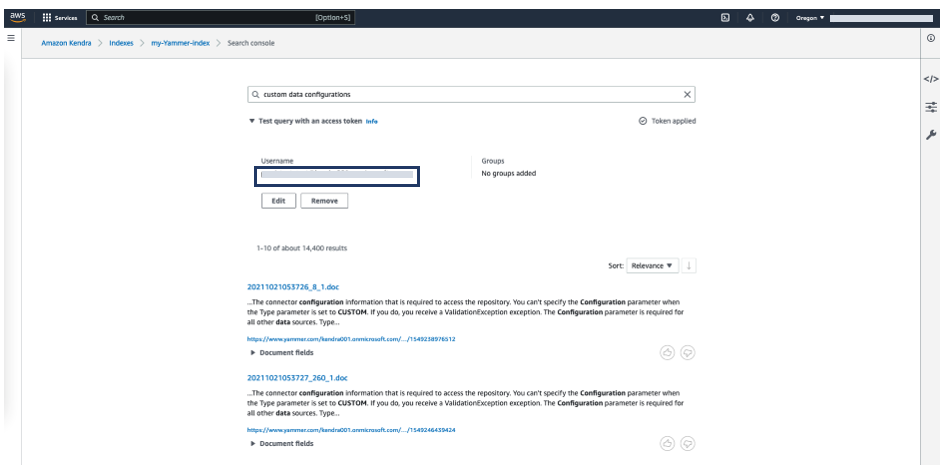
- To use this feature, go back to the search results page.
- Expand Test query with user name or groups and choose Apply user name or groups.

For Yammer, we don’t import groups, we just import user names. User names are email IDs in this case.
- Enter the user ID (email) of your user and choose Apply.

The following screenshot shows the updated search results.
When fronting Amazon Kendra with an application such as an application built using Experience Builder, you can pass the user identity (in the form of the email ID) to Amazon Kendra to ensure that each user only sees content specific to their user ID. Alternately, you can use AWS IAM Identity Center (successor to AWS Single Sign-On) to control user context being passed to Amazon Kendra to limit queries by user.
Congratulations! You have successfully used Amazon Kendra to surface answers and insights based on the content indexed from your Yammer account.
Limitations
This solution has the following limitations:
- Only the export API is available to fetch all communities. API support for fetching event details, votes about polls, and update messages is not available as of this writing.
- Deleted entities such as messages, attachments, communities, and users are not crawled in change log crawl mode. You need to run another full crawl to get the updated information on deletion of all the entities.
- For communities, the following are not part of indexing:
- Community insight details
- Community information
- Related communities for that community
- Files uploaded directly into the community without any attachment to a message
- Yammer has rate limits that govern the speed of ingestion. For more information, refer to Limits in Yammer.
Clean up
To avoid incurring future costs, clean up the resources you created as part of this solution. If you created a new Amazon Kendra index while testing this solution, delete it. If you only added a new data source using the Amazon Kendra connector for Yammer, delete that data source.
Conclusion
With the Yammer connector for Amazon Kendra, organizations can tap into the repository of information stored in their account securely using intelligent search powered by Amazon Kendra.
To learn about these possibilities and more, refer to the Amazon Kendra Developer Guide. For more information on how you can create, modify, or delete metadata and content when ingesting your data from Yammer, refer to Enriching your documents during ingestion and Enrich your content and metadata to enhance your search experience with custom document enrichment in Amazon Kendra.
About the authors
 Senthil Ramachandran is an Enterprise Solutions Architect at AWS, supporting customers in the US North East. He is primarily focused on Cloud adoption and Digital Transformation in Financial Services Industry. Senthil’s area of interest is AI, especially Deep Learning and Machine Learning. He focuses on application automations with continuous learning and improving human enterprise experience. Senthil enjoys watching Autosport, Soccer and spending time with his family.
Senthil Ramachandran is an Enterprise Solutions Architect at AWS, supporting customers in the US North East. He is primarily focused on Cloud adoption and Digital Transformation in Financial Services Industry. Senthil’s area of interest is AI, especially Deep Learning and Machine Learning. He focuses on application automations with continuous learning and improving human enterprise experience. Senthil enjoys watching Autosport, Soccer and spending time with his family.