
This is a guest blog post co-written with Vik Pant and Kyle Bassett from PwC.
With organizations increasingly investing in machine learning (ML), ML adoption has become an integral part of business transformation strategies. A recent PwC CEO survey unveiled that 84% of Canadian CEOs agree that artificial intelligence (AI) will significantly change their business within the next 5 years, making this technology more critical than ever. However, implementing ML into production comes with various considerations, notably being able to navigate the world of AI safely, strategically, and responsibly. One of the first steps and notably a great challenge to becoming AI powered is effectively developing ML pipelines that can scale sustainably in the cloud. Thinking of ML in terms of pipelines that generate and maintain models rather than models by themselves helps build versatile and resilient prediction systems that are better able to withstand meaningful changes in relevant data over time.
Many organizations start their journey into the world of ML with a model-centric viewpoint. In the early stages of building an ML practice, the focus is on training supervised ML models, which are mathematical representations of relationships between inputs (independent variables) and outputs (dependent variables) that are learned from data (typically historical). Models are mathematical artifacts that take input data, perform calculations and computations on them, and generate predictions or inferences.
Although this approach is a reasonable and relatively simple starting point, it isn’t inherently scalable or intrinsically sustainable due to the manual and ad hoc nature of model training, tuning, testing, and trialing activities. Organizations with greater maturity in the ML domain adopt an ML operations (MLOps) paradigm that incorporates continuous integration, continuous delivery, continuous deployment, and continuous training. Central to this paradigm is a pipeline-centric viewpoint for developing and operating industrial-strength ML systems.
In this post, we start with an overview of MLOps and its benefits, describe a solution to simplify its implementations, and provide details on the architecture. We finish with a case study highlighting the benefits realize by a large AWS and PwC customer who implemented this solution.
Background
An MLOps pipeline is a set of interrelated sequences of steps that are used to build, deploy, operate, and manage one or more ML models in production. Such a pipeline encompasses the stages involved in building, testing, tuning, and deploying ML models, including but not limited to data preparation, feature engineering, model training, evaluation, deployment, and monitoring. As such, an ML model is the product of an MLOps pipeline, and a pipeline is a workflow for creating one or more ML models. Such pipelines support structured and systematic processes for building, calibrating, assessing, and implementing ML models, and the models themselves generate predictions and inferences. By automating the development and operationalization of stages of pipelines, organizations can reduce the time to delivery of models, increase the stability of the models in production, and improve collaboration between teams of data scientists, software engineers, and IT administrators.
Solution overview
AWS offers a comprehensive portfolio of cloud-native services for developing and running MLOps pipelines in a scalable and sustainable manner. Amazon SageMaker comprises a comprehensive portfolio of capabilities as a fully managed MLOps service to enable developers to create, train, deploy, operate, and manage ML models in the cloud. SageMaker covers the entire MLOps workflow, from collecting to preparing and training the data with built-in high-performance algorithms and sophisticated automated ML (AutoML) experiments so that companies can choose specific models that fit their business priorities and preferences. SageMaker enables organizations to collaboratively automate the majority of their MLOps lifecycle so that they can focus on business results without risking project delays or escalating costs. In this way, SageMaker allows businesses to focus on results without worrying about infrastructure, development, and maintenance associated with powering industrial-strength prediction services.
SageMaker includes Amazon SageMaker JumpStart, which offers out-of-the-box solution patterns for organizations seeking to accelerate their MLOps journey. Organizations can start with pre-trained and open-source models that can be fine-tuned to meet their specific needs through retraining and transfer learning. Additionally, JumpStart provides solution templates designed to tackle common use cases, as well as example Jupyter notebooks with prewritten starter code. These resources can be accessed by simply visiting the JumpStart landing page within Amazon SageMaker Studio.
PwC has built a pre-packaged MLOps accelerator that further speeds up time to value and increases return on investment for organizations that use SageMaker. This MLOps accelerator enhances the native capabilities of JumpStart by integrating complementary AWS services. With a comprehensive suite of technical artifacts, including infrastructure as code (IaC) scripts, data processing workflows, service integration code, and pipeline configuration templates, PwC’s MLOps accelerator simplifies the process of developing and operating production-class prediction systems.
Architecture overview
The inclusion of cloud-native serverless services from AWS is prioritized into the architecture of the PwC MLOps accelerator. The entry point into this accelerator is any collaboration tool, such as Slack, that a data scientist or data engineer can use to request an AWS environment for MLOps. Such a request is parsed and then fully or semi-automatically approved using workflow features in that collaboration tool. After a request is approved, its details are used for parameterizing IaC templates. The source code for these IaC templates is managed in AWS CodeCommit. These parameterized IaC templates are submitted to AWS CloudFormation for modeling, provisioning, and managing stacks of AWS and third-party resources.
The following diagram illustrates the workflow.
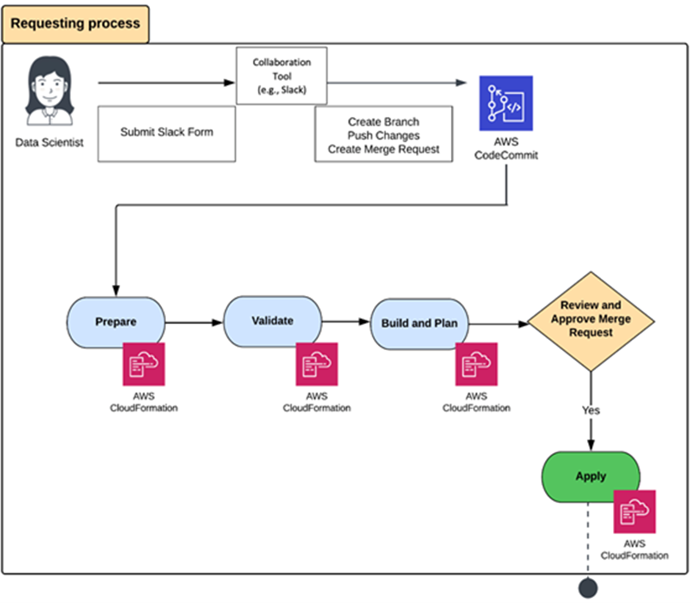
After AWS CloudFormation provisions an environment for MLOps on AWS, the environment is ready for use by data scientists, data engineers, and their collaborators. The PWC accelerator includes predefined roles on AWS Identity and Access Management (IAM) that are related to MLOps activities and tasks. These roles specify the services and resources in the MLOps environment that can be accessed by various users based on their job profiles. After accessing the MLOps environment, users can access any of the modalities on SageMaker to perform their duties. These include SageMaker notebook instances, Amazon SageMaker Autopilot experiments, and Studio. You can benefit from all SageMaker features and functions, including model training, tuning, evaluation, deployment, and monitoring.
The accelerator also includes connections with Amazon DataZone for sharing, searching, and discovering data at scale across organizational boundaries to generate and enrich models. Similarly, data for training, testing, validating, and detecting model drift can source a variety of services, including Amazon Redshift, Amazon Relational Database Service (Amazon RDS), Amazon Elastic File System (Amazon EFS), and Amazon Simple Storage Service (Amazon S3). Prediction systems can be deployed in many ways, including as SageMaker endpoints directly, SageMaker endpoints wrapped in AWS Lambda functions, and SageMaker endpoints invoked through custom code on Amazon Elastic Kubernetes Service (Amazon EKS) or Amazon Elastic Compute Cloud (Amazon EC2). Amazon CloudWatch is used to monitor the environment for MLOps on AWS in a comprehensive manner to observe alarms, logs, and events data from across the complete stack (applications, infrastructure, network, and services).
The following diagram illustrates this architecture.

Case study
In this section, we share an illustrative case study from a large insurance company in Canada. It focuses on the transformative impact of the implementation of PwC Canada’s MLOps accelerator and JumpStart templates.
This client partnered with PwC Canada and AWS to address challenges with inefficient model development and ineffective deployment processes, lack of consistency and collaboration, and difficulty in scaling ML models. The implementation of this MLOps Accelerator in concert with JumpStart templates achieved the following:
- End-to-end automation – Automation nearly halved the amount of time for data preprocessing, model training, hyperparameter tuning, and model deployment and monitoring
- Collaboration and standardization – Standardized tools and frameworks to promote consistency across the organization nearly doubled the rate of model innovation
- Model governance and compliance – They implemented a model governance framework to ensure that all ML models met regulatory requirements and adhered to the company’s ethical guidelines, which reduced risk management costs by 40%
- Scalable cloud infrastructure – They invested in scalable infrastructure to effectively manage massive data volumes and deploy multiple ML models simultaneously, reducing infrastructure and platform costs by 50%
- Rapid deployment – The prepackaged solution reduced time to production by 70%
By delivering MLOps best practices through rapid deployment packages, our client was able to de-risk their MLOps implementation and unlock the full potential of ML for a range of business functions, such as risk prediction and asset pricing. Overall, the synergy between the PwC MLOps accelerator and JumpStart enabled our client to streamline, scale, secure, and sustain their data science and data engineering activities.
It should be noted that the PwC and AWS solution is not industry specific and is relevant across industries and sectors.
Conclusion
SageMaker and its accelerators allow organizations to enhance the productivity of their ML program. There are many benefits, including but not limited to the following:
- Collaboratively create IaC, MLOps, and AutoML use cases to realize business benefits from standardization
- Enable efficient experimental prototyping, with and without code, to turbocharge AI from development to deployment with IaC, MLOps, and AutoML
- Automate tedious, time-consuming tasks such as feature engineering and hyperparameter tuning with AutoML
- Employ a continuous model monitoring paradigm to align the risk of ML model usage with enterprise risk appetite
Please contact the authors of this post, AWS Advisory Canada, or PwC Canada to learn more about Jumpstart and PwC’s MLOps accelerator.
About the Authors
 Vik is a Partner in the Cloud & Data practice at PwC Canada He earned a PhD in Information Science from the University of Toronto. He is convinced that there is a telepathic connection between his biological neural network and the artificial neural networks that he trains on SageMaker. Connect with him on LinkedIn.
Vik is a Partner in the Cloud & Data practice at PwC Canada He earned a PhD in Information Science from the University of Toronto. He is convinced that there is a telepathic connection between his biological neural network and the artificial neural networks that he trains on SageMaker. Connect with him on LinkedIn.
 Kyle is a Partner in the Cloud & Data practice at PwC Canada, along with his crack team of tech alchemists, they weave enchanting MLOPs solutions that mesmerize clients with accelerated business value. Armed with the power of artificial intelligence and a sprinkle of wizardry, Kyle turns complex challenges into digital fairy tales, making the impossible possible. Connect with him on LinkedIn.
Kyle is a Partner in the Cloud & Data practice at PwC Canada, along with his crack team of tech alchemists, they weave enchanting MLOPs solutions that mesmerize clients with accelerated business value. Armed with the power of artificial intelligence and a sprinkle of wizardry, Kyle turns complex challenges into digital fairy tales, making the impossible possible. Connect with him on LinkedIn.
 Francois is a Principal Advisory Consultant with AWS Professional Services Canada and the Canadian practice lead for Data and Innovation Advisory. He guides customers to establish and implement their overall cloud journey and their data programs, focusing on vision, strategy, business drivers, governance, target operating models, and roadmaps. Connect with him on LinkedIn.
Francois is a Principal Advisory Consultant with AWS Professional Services Canada and the Canadian practice lead for Data and Innovation Advisory. He guides customers to establish and implement their overall cloud journey and their data programs, focusing on vision, strategy, business drivers, governance, target operating models, and roadmaps. Connect with him on LinkedIn.