
Financial market participants are faced with an overload of information that influences their decisions, and sentiment analysis stands out as a useful tool to help separate out the relevant and meaningful facts and figures. However, the same piece of news can have a positive or negative impact on stock prices, which presents a challenge for this task. Sentiment analysis and other natural language programming (NLP) tasks often start out with pre-trained NLP models and implement fine-tuning of the hyperparameters to adjust the model to changes in the environment. Transformer-based language models such as BERT (Bidirectional Transformers for Language Understanding) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. To account for changes in the economic environment, the model needs to be fine-tuned once more when the data starts drifting or the model’s prediction accuracy starts to degrade.
Hyperparameter optimization is highly computationally demanding for deep learning models. The architectural complexity increases when a single model training run requires multiple GPUs. In this post, we use the Weights & Biases (W&B) Sweeps function and Amazon Elastic Kubernetes Service (Amazon EKS) to address these challenges. Amazon EKS is a highly available managed Kubernetes service that automatically scales instances based on load, and is well suited for running distributed training workloads.
In our solution, we implement a hyperparameter grid search on an EKS cluster for tuning a bert-base-cased model for classifying positive or negative sentiment for stock market data headlines. The code can be found on the GitHub repo.
Solution overview
In this post, we present an overview of the solution architecture and discuss its key components. More specifically, we discuss the following:
- How to set up an EKS cluster with a scalable file system
- How to train PyTorch models using TorchElastic
- Why the W&B platform is the right choice for machine learning (ML) experimentation and hyperparameter grid search
- A solution architecture integrating W&B with EKS and TorchElastic
Prerequisites
To follow along with the solution, you should have an understanding of PyTorch, distributed data parallel (DDP) training, and Kubernetes.
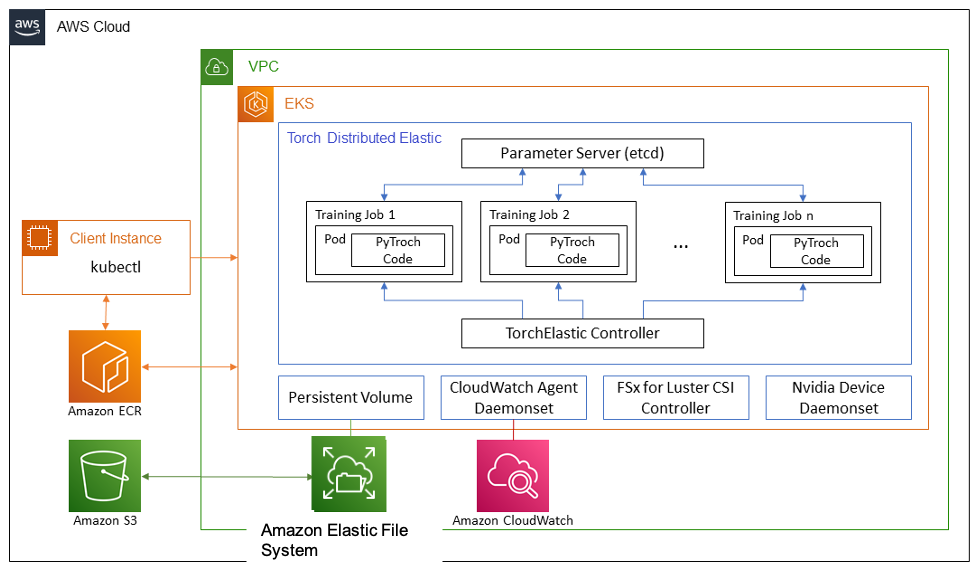
Set up an EKS cluster with a scalable file system
One way to get started with Amazon EKS is aws-do-eks, which is an open-source project offering easy-to-use and configurable scripts and tools to provision EKS clusters and run distributed training jobs. This project is built following the principles of the Do Framework: simplicity, intuitiveness, and productivity. A desired cluster can simply be configured using the eks.conf file and launched by running the eks-create.sh script. Detailed instructions are provided in the GitHub repository for aws-do-eks.
The following diagram illustrates the EKS cluster architecture.

Some helpful tips when creating an EKS cluster with aws-do-eks:
- Make sure
CLUSTER_REGIONin conf is the same as your default Region when you do aws configure. - Creating an EKS cluster can take up to 30 minutes. We recommended creating an aws-do-eks container like the GitHub repo suggests to ensure consistency and simplicity because the container has all the necessary tools such as kubectl, aws cli, eksctl, and so on. Then you can run into the container and run
./eks-create.shto launch the cluster. - Unless you specify Spot Instances in conf, instances will be created on demand.
- You can specify custom AMIs or specific zones for different instance types.
- The
./eks-create.shscript will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources. This will create one instance of each type. Then./eks-scale.shwill scale your node groups to the desired sizes. - After the cluster is created, AWS Identity and Access Management (IAM) roles are generated with Amazon EKS related policies for each instance type. Policies may be needed to access Amazon Simple Storage Service (Amazon S3) or other services with these roles.
- The following are common reasons why the
./eks-create.shscript might give an error:- Node groups fail to get created because of insufficient capacity. Check instance availability in the requested Region and your capacity limits.
- A specific instance type may not be available or supported in a given zone.
- The EKS cluster creation AWS CloudFormation stacks aren’t properly deleted. Check the active CloudFormation stacks to see if stack deletion has failed.
A scalable shared file system is needed so that multiple compute nodes in the EKS cluster can access concurrently. In this post, we use Amazon Elastic File System (Amazon EFS) as a shared file system that is elastic and provides high throughput. The scripts in aws-do-eks/Container-Root/eks/deployment/csi/ provide instructions to mount Amazon EFS on an EKS cluster. After the cluster is created and the node groups are scaled to the desired number of instances, you can view the running pods with kubectl get pod -A. Here the aws-node-xxxx, kube-proxy-xxxx, and nvidia-device-plugin-daemonset-xxxx pods run on each of the three compute nodes, and we have one system node in the kube-system namespace.
Before proceeding to create and mount an EFS volume, make sure you are in the kube-system namespace. If not, you can change it with the following code:
Then view the running pods with kubectl get pod -A.

The efs-create.sh script will create the EFS volume and mount targets in each subnet and the persistent volume. Then a new EFS volume will be visible on the Amazon EFS console.
Next, run the ./deploy.sh script to get the EFS files system ID, deploy an EFS-CSI driver on each node group, and mount the EFS persistent volume using the efs-sc.yaml and efs-pv.yaml manifest files. You can validate whether a persistent volume is mounted by checking kubectl get pv. You can also run kubectl apply -f efs-share-test.yaml, which will spin up an efs-share-test pod in the default namespace. This is a test pod that writes “hello from EFS” in the /shared-efs/test.txt file. You can run into a pod using kubectl exec -it <pod-name> -- bash. To move data from Amazon S3 to Amazon EFS, efs-data-prep-pod.yaml gives an example manifest file, assuming a data-prep.sh script exists in a Docker image that copies data from Amazon S3 to Amazon EFS.
If your model training needs higher throughput, Amazon FSx for Lustre might be a better option.
Train PyTorch models using TorchElastic
For deep learning models that train on amounts of data too large to fit in memory on a single GPU, DistributedDataParallel (PyTorch DDP) will enable the sharding of large training data into mini batches across multiple GPUs and instances, reducing training time.
TorchElastic is a PyTorch library developed with a native Kubernetes strategy supporting fault tolerance and elasticity. When training on Spot Instances, the training needs to be fault tolerant and able to resume from the epoch where the compute nodes left when the Spot Instances were last available. Elasticity allows for the seamless addition of new compute resources when available or removal of resources when they are needed elsewhere.
The following figure illustrates the architecture for DistributedDataParallel with TorchElastic. TorchElastic for Kubernetes consists of two components: TorchElastic Kubernetes Controller and the parameter server (etcd). The controller is responsible for monitoring and managing the training jobs, and the parameter server keeps track of the training job workers for distributed synchronization and peer discovery.
W&B platform for ML experimentation and hyperparameter grid search
W&B helps ML teams build better models faster. With just a few lines of code, you can instantly debug, compare, and reproduce your models—architecture, hyperparameters, git commits, model weights, GPU usage, datasets, and predictions—while collaborating with your teammates.

W&B Sweeps is a powerful tool to automate hyperparameter optimization. It allows developers to set up the hyperparameter search strategy, including grid search, random search, or Bayesian search, and it will automatically implement each training run.
To try W&B for free, sign up at Weights & Biases, or visit the W&B AWS Marketplace listing.
Integrate W&B with Amazon EKS and TorchElastic
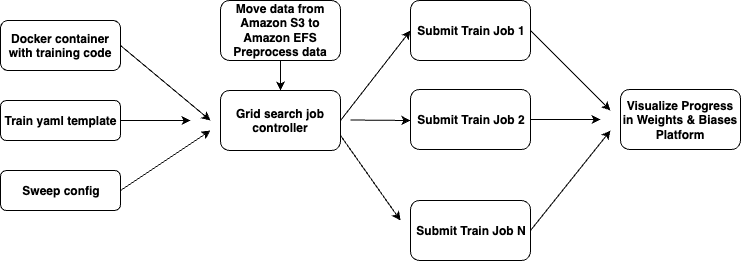
The following figure illustrates the end-to-end process flow to orchestrate multiple DistributedDataParallel training runs on Amazon EKS with TorchElastic based on a W&B sweep config. Specifically, the steps involved are:
- Move data from Amazon S3 to Amazon EFS.
- Load and preprocess data with W&B.
- Build a Docker image with the training code and all necessary dependencies, then push the image to Amazon ECR.
- Deploy the TorchElastic controller.
- Create a W&B sweep config file containing all hyperparameters that need to be swept and their ranges.
- Create a yaml manifest template file that takes inputs from the sweep config file.
- Create a Python job controller script that creates N training manifest files, one for each training run, and submits the jobs to the EKS cluster.
- Visualize results on the W&B platform.
In the following sections, we walk through each step in more detail.
Move data from Amazon S3 to Amazon EFS
The first step is to move training, validation, and test data from Amazon S3 to Amazon EFS so all EKS compute nodes can access it. The s3_efs folder has the scripts to move data from Amazon S3 to Amazon EFS. Following the Do Framework, we need a basic Dockerfile that creates a container with a data-prep.sh script, build.sh script, and push.sh script to build the image and push it to Amazon ECR. After a Docker image is pushed to Amazon ECR, you can use the efs-data-prep-pod.yaml manifest file (see the following code), which you can run like kubectl apply -f efs-data-prep-pod.yaml to run the data-prep.sh script in a pod:
apiVersion: v1
kind: ConfigMap
metadata
name: efs-data-prep-map
data:
S3_BUCKET:<S3 Bucket URI with data>
MOUNT_PATH: /shared-efs
---
apiVersion: v1
kind: Pod
metadata:
name: efs-data-prep-pod
spec:
containers:
- name: efs-data-prep-pod
image: <Path to Docker image in ECR>
envFrom:
- configMapRef:
name: efs-data-prep-map
command: ["/bin/bash"]
args: ["-c", "/data-prep.sh $(S3_BUCKET) $(MOUNT_PATH)"]
volumeMounts:
- name: efs-pvc
mountPath: /shared-efs
volumes:
- name: efs-pvc
persistentVolumeClaim:
claimName: efs-claim
restartPolicy: Never
Load and preprocess data with W&B
The process to submit a preprocessing job is very similar to the preceding step, with a few exceptions. Instead of a data-prep.sh script, you likely need to run a Python job to preprocess the data. The preprocess folder has the scripts to run a preprocessing job. The pre-process_data.py script accomplishes two tasks: it takes in the raw data in Amazon EFS and splits it into train and test files, then it adds the data to the W&B project.
Build a Docker image with training code
main.py demonstrates how to implement DistributedDataParallel training with TorchElastic. For compatibility with W&B, it’s standard practice to add WANDB_API_KEY as an environment variable and add wandb.login() at the very beginning of the code. In addition to the standard arguments (number of epochs, batch size, number of workers for the data loader), we need to pass in wandb_project name and sweep_id as well.
In the main.py code, the run() function stores the end-to-end pipeline for the following actions:
- Initializing wandb on node 0 for logging results
- Loading the pre-trained model and setting up the optimizer
- Initializing custom training and validation data loaders
- Loading and saving checkpoints at every epoch
- Looping through the epochs and calling the training and validation functions
- After training is done, running predictions on the specified test set
The training, validation, custom data loader, and collate functions don’t need to be changed to log results to W&B. For a distributed training setup, we need to add the following block of code to log on the node 0 process. Here, args are the parameters for the training function in addition to the sweep ID and W&B project name:
if local_rank == 0:
wandb.init(config=args, project=args.wandb_project)
args = wandb.config
do_log = True
else:
do_log = False
For more information on W&B and distributed training, refer to Log distributed training experiments.
In the main() function, you can call the run() function as shown in the following code. Here the wandb.agent is the orchestrator of the sweep, but because we’re running multiple training jobs on Amazon EKS in parallel, we need to specify count = 1:
wandb.require("service")
wandb.setup()
if args.sweep_id is not None:
wandb.agent(args.sweep_id, lambda: run(args), project=args.wandb_project, count = 1)
else:
run(args=args)
The Dockerfile installs the necessary dependencies for PyTorch, HuggingFace, and W&B, and specifies a Python call to torch.distributed.run as an entry point.
Deploy a TorchElastic Controller
Before training, we need to deploy a TorchElastic Controller for Kubernetes, which manages a Kubernetes custom resource ElasticJob to run TorchElastic workloads on Kubernetes. We also deploy a pod running the etcd server by running the script deploy.sh. It is recommended to delete and restart the etcd server when restarting a fresh training job.
W&B sweep config
After setting up the cluster and the container, we set up multiple runs in parallel with slightly different parameters in order to improve our model performance. W&B Sweeps will automate this kind of exploration. We set up a configuration file where we define the search strategy, the metric to monitor, and the parameters to explore. The following code shows an example sweep config file:
method: bayes
metric:
name: val_loss
goal: minimize
parameters:
learning_rate:
min: 0.001
max: 0.1
optimizer:
values: ["adam", "sgd"]
For more details on how to configure your sweeps, follow the W&B Sweeps Quickstart.
Create a train.yaml template
The following code is an example of the train.yaml template that we need to create. The Python job controller will take this template and generate one training .yaml file for each run in the hyperparameter grid search. Some key points to note are:
- The
kubernetes.io/instance-typevalue takes in the name of the instance type of the EKS compute nodes. - The args section includes all parameters that the py code takes in as arguments, including number of epochs, batch size, number of data loader workers,
sweep_id, wandb project name, checkpoint file location, data directory location, and so on. - The
--nproc_per_nodeandnvidia.com/gpuvalues take in the number of GPUs you want to use for training. For example, in the following config, we have p3.8xlarge as the EKS compute nodes, which have 4 Nvidia Tesla V100 GPUs, and in each training run we use 2 GPUs. We can kick off six training runs in parallel that will exhaust all available 12 GPUs, thereby ensuring high GPU utilization.
apiVersion: elastic.pytorch.org/v1alpha1
kind: ElasticJob
metadata:
name: wandb-finbert-baseline
#namespace: elastic-job
spec:
# Use "etcd-service:2379" if you already apply etcd.yaml
rdzvEndpoint: etcd-service:2379
minReplicas: 1
maxReplicas: 128
replicaSpecs:
Worker:
replicas: 1
restartPolicy: ExitCode
template:
apiVersion: v1
kind: Pod
spec:
nodeSelector:
node.kubernetes.io/instance-type: p3.8xlarge
containers:
- name: elasticjob-worker
image: <path to docker image in ECR>
imagePullPolicy: Always
env:
- name: NCCL_DEBUG
value: INFO
# - name: NCCL_SOCKET_IFNAME
# value: lo
# - name: FI_PROVIDER
# value: sockets
args:
- "--nproc_per_node=2"
- "/workspace/examples/huggingface/main.py"
- "--data=/shared-efs/wandb-finbert/"
- "--epochs=1"
- "--batch-size=16"
- "--workers=6"
- "--wandb_project=aws_eks_demo"
- "--sweep_id=jba9d36p"
- "--checkpoint-file=/shared-efs/wandb-finbert/job-z74e8ix8/run-baseline/checkpoint.tar"
resources:
limits:
nvidia.com/gpu: 2
volumeMounts:
- name: efs-pvc
mountPath: /shared-efs
- name: dshm
mountPath: /dev/shm
volumes:
- name: efs-pvc
persistentVolumeClaim:
claimName: efs-claim
- name: dshm
emptyDir:
medium: Memory
Create a grid search job controller
The script run-grid.py is the key orchestrator that takes in a TorchElastic training .yaml template and W&B sweep config file, generates multiple training manifest files, and submits them.
Visualize the results
We set up an EKS cluster with three p3.8xlarge instances with 4 Tesla V100 GPUs each. We set up six parallel runs with 2 GPUs each, while varying learning rate and weight decay parameters for the Adam optimizer. Each individual training run would take roughly 25 minutes, so the entire hyperparameter grid could be swept in 25 minutes when operating in parallel as opposed to 150 minutes if operating sequentially. If desired, a single GPU can be used for each training round by changing the --nproc_per_node and nvidia.com/gpu values in the training .yaml template.
TorchElastic implements elasticity and fault tolerance. In this work, we are using On-Demand instances, but a cluster of Spot Instances can be generated with a few changes in the EKS config. If an instance becomes available at a later time and needs to be added to the training pool while the training is going on, we just need to update the training .yaml template and resubmit it. The rendezvous functionality of TorchElastic will assimilate the new instance in the training job dynamically.
Once the grid search job controller is running, you can see all six Kubernetes jobs with kubectl get pod -A. There will be one job per training run, and each job will have one worker per node. To see the logs for each pod, you can tail logs using kubectl logs -f <pod-name>. kubetail will display the logs of all pods for each training job simultaneously. At the start of the grid controller, you get a link to the W&B platform where you can view the progress of all jobs.
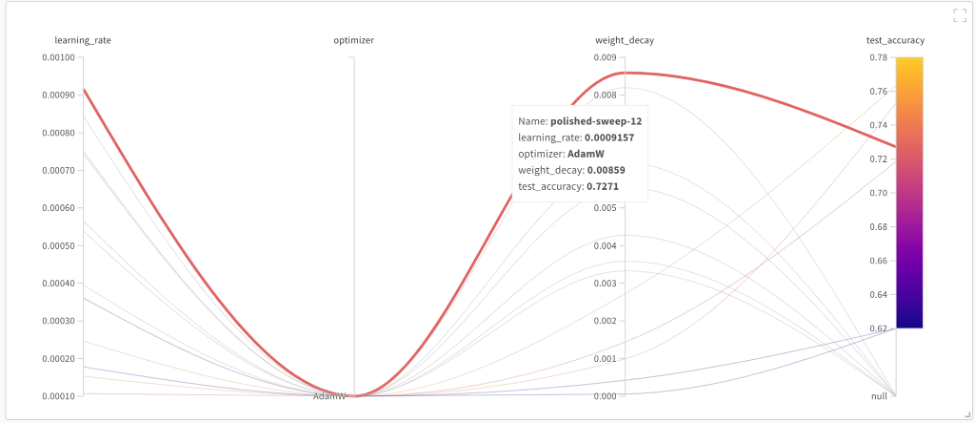
The following parallel coordinates graph visualizes all grid search runs with respect to test accuracy in one plot, including those that didn’t finish. We got the highest test accuracy with a learning rate of 9.1e-4 and weight decay of 8.5e-3.
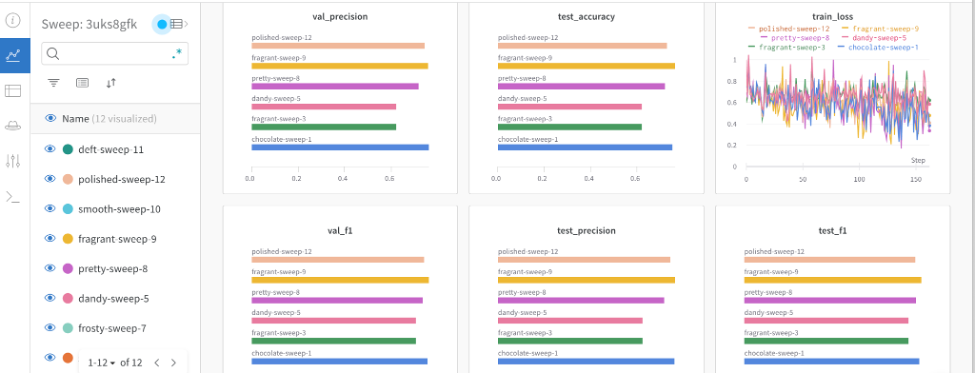
The following dashboard visualizes all grid search runs together for all metrics.
Clean up
It’s important to spin down resources after model training in order to avoid costs associated with running idle instances. With each script that creates resources, the GitHub repo provides a matching script to delete them. To clean up our setup, we must delete the EFS file system before deleting the cluster because it’s associated with a subnet in the cluster’s VPC. To delete the EFS file system, run the following command (from inside the efs folder):
Note that this will not only delete the persistent volume, it will also delete the EFS file system, and all the data on the file system will be lost. When this step is complete, delete the cluster by using the following script in the eks folder:
This will delete all the existing pods, remove the cluster, and delete the VPC created in the beginning.
Conclusion
In this post, we showed how to use an EKS cluster with Weights & Biases to accelerate hyperparameter grid search for deep learning models. Weights & Biases and Amazon EKS enables you to orchestrate multiple training runs in parallel to reduce time and cost to fine-tune your deep learning model. We have published the GitHub repo, which gives you step-by-step instructions to create an EKS cluster, set up Weights & Biases and TorchElastic for distributed data parallel training, and kickstart grid search runs on Amazon EKS with one click.
About the authors
Ankur Srivastava is a Sr. Solutions Architect in the ML Frameworks Team. He focuses on helping customers with self-managed distributed training and inference at scale on AWS. His experience includes industrial predictive maintenance, digital twins, probabilistic design optimization and has completed his doctoral studies from Mechanical Engineering at Rice University and post-doctoral research from Massachusetts Institute of Technology.
Thomas Chapelle is a Machine Learning Engineer at Weights and Biases. He is responsible for keeping the www.github.com/wandb/examples repository live and up to date. He also builds content on MLOPS, applications of W&B to industries, and fun deep learning in general. Previously he was using deep learning to solve short-term forecasting for solar energy. He has a background in Urban Planning, Combinatorial Optimization, Transportation Economics, and Applied Math.
Scott Juang is the Director of Alliances at Weights & Biases. Prior to W&B, he led a number of strategic alliances at AWS and Cloudera. Scott studied Materials Engineering and has a passion for renewable energy.
Ilan Gleiser is a Principal Global Impact Computing Specialist at AWS leading the Circular Economy, Responsible AI and ESG businesses. He is an Expert Advisor of Digital Technologies for Circular Economy with United Nations. Prior to AWS, he led AI Enterprise Solutions at Wells Fargo. He spent 10 years as Head of Morgan Stanley’s Algorithmic Trading Division in San Francisco.
Ana Simoes is a Principal ML Specialist at AWS focusing on GTM strategy for startups in the emerging technology space. Ana has had several leadership roles at startups and large corporations such as Intel and eBay, leading ML inference and linguistics related products. Ana has a Masters in Computational Linguistics and an MBA form Haas/UC Berkeley, and and has been a visiting scholar in Linguistics at Stanford. She has a technical background in AI and Natural Language Processing.