This is a guest post from Scalable Capital, a leading FinTech in Europe that offers digital wealth management and a brokerage platform with a trading flat rate.
As a fast-growing company, Scalable Capital’s goals are to not only build an innovative, robust, and reliable infrastructure, but to also provide the best experiences for our clients, especially when it comes to client services.
Scalable receives hundreds of email inquiries from our clients on a daily basis. By implementing a modern natural language processing (NLP) model, the response process has been shaped much more efficiently, and waiting time for clients has been reduced tremendously. The machine learning (ML) model classifies new incoming customer requests as soon as they arrive and redirects them to predefined queues, which allows our dedicated client success agents to focus on the contents of the emails according to their skills and provide appropriate responses.
In this post, we demonstrate the technical benefits of using Hugging Face transformers deployed with Amazon SageMaker, such as training and experimentation at scale, and increased productivity and cost-efficiency.
Problem statement
Scalable Capital is one of the fastest growing FinTechs in Europe. With the aim to democratize investment, the company provides its clients with easy access to the financial markets. Clients of Scalable can actively participate in the market through the company’s brokerage trading platform, or use Scalable Wealth Management to invest in an intelligent and automated fashion. In 2021, Scalable Capital experienced a tenfold increase of its client base, from tens of thousands to hundreds of thousands.
To provide our clients with a top-class (and consistent) user experience across products and client service, the company was looking for automated solutions to generate efficiencies for a scalable solution while maintaining operational excellence. Scalable Capital’s data science and client service teams identified that one of the largest bottlenecks in servicing our clients was responding to email inquiries. Specifically, the bottleneck was the classification step, in which employees had to read and label request texts on a daily basis. After the emails were routed to their proper queues, the respective specialists quickly engaged and resolved the cases.
To streamline this classification process, the data science team at Scalable built and deployed a multitask NLP model using state-of-the-art transformer architecture, based on the pre-trained distilbert-base-german-cased model published by Hugging Face. distilbert-base-german-cased uses the knowledge distillation method to pretrain a smaller general-purpose language representation model than the original BERT base model. The distilled version achieves comparable performance to the original version, while being smaller and faster. To facilitate our ML lifecycle process, we decided to adopt SageMaker to build, deploy, serve, and monitor our models. In the following section, we introduce our project architecture design.
Solution overview
Scalable Capital’s ML infrastructure consists of two AWS accounts: one as an environment for the development stage and the other one for the production stage.
The following diagram shows the workflow for our email classifier project, but can also be generalized to other data science projects.
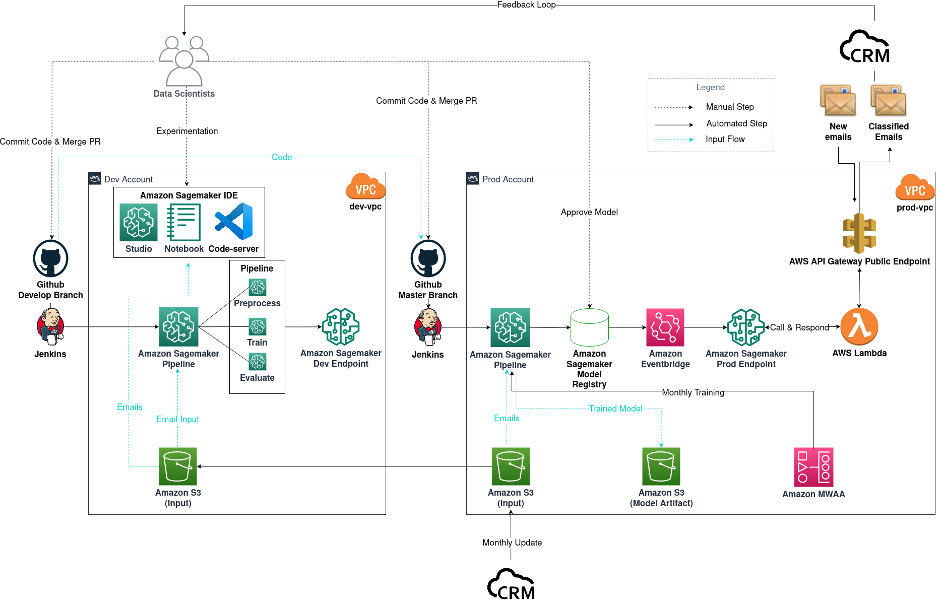
Email classification project diagram
The workflow consists of the following components:
- Model experimentation – Data scientists use Amazon SageMaker Studio to carry out the first steps in the data science lifecycle: exploratory data analysis (EDA), data cleaning and preparation, and building prototype models. When the exploratory phase is complete, we turn to VSCode hosted by a SageMaker notebook as our remote development tool to modularize and productionize our code base. To explore different types of models and model configurations, and at the same time to keep track of our experimentations, we use SageMaker Training and SageMaker Experiments.
- Model build – After we decide on a model for our production use case, in this case a multi-task distilbert-base-german-cased model, fine-tuned from the pretrained model from Hugging Face, we commit and push our code to Github develop branch. The Github merge event triggers our Jenkins CI pipeline, which in turn starts a SageMaker Pipelines job with test data. This acts as a test to make sure that codes are running as expected. A test endpoint is deployed for testing purposes.
- Model deployment – After making sure that everything is running as expected, data scientists merge the develop branch into the primary branch. This merge event now triggers a SageMaker Pipelines job using production data for training purposes. Afterwards, model artifacts are produced and stored in an output Amazon Simple Storage Service (Amazon S3) bucket, and a new model version is logged in the SageMaker model registry. Data scientists examine the performance of the new model, then approve if it’s in line with expectations. The model approval event is captured by Amazon EventBridge, which then deploys the model to a SageMaker endpoint in the production environment.
- MLOps – Because the SageMaker endpoint is private and can’t be reached by services outside of the VPC, an AWS Lambda function and Amazon API Gateway public endpoint are required to communicate with CRM. Whenever new emails arrive in the CRM inbox, CRM invokes the API Gateway public endpoint, which in turn triggers the Lambda function to invoke the private SageMaker endpoint. The function then relays the classification back to CRM through the API Gateway public endpoint. To monitor the performance of our deployed model, we implement a feedback loop between CRM and the data scientists to keep track of prediction metrics from the model. On a monthly basis, CRM updates the historical data used for experimentation and model training. We use Amazon Managed Workflows for Apache Airflow (Amazon MWAA) as a scheduler for our monthly retrain.
In the following sections, we break down the data preparation, model experimentation, and model deployment steps in more detail.
Data preparation
Scalable Capital uses a CRM tool for managing and storing email data. Relevant email contents consist of subject, body, and the custodian banks. There are three labels to assign to each email: which line of business the email is from, which queue is appropriate, and the specific topic of the email.
Before we start training any NLP models, we ensure that the input data is clean and the labels are assigned according to expectation.
To retrieve clean inquiry contents from Scalable clients, we remove from raw email data and extra text and symbols, such as email signatures, impressums, quotes of previous messages in email chains, CSS symbols, and so on. Otherwise, our future trained models might experience degraded performance.
Labels for emails evolve over time as Scalable client service teams add new ones and refine or remove existing ones to accommodate business needs. To make sure that labels for training data as well as expected classifications for prediction are up to date, the data science team works in close collaboration with the client service team to ensure the correctness of the labels.
Model experimentation
We start our experiment with the readily available pre-trained distilbert-base-german-cased model published by Hugging Face. Because the pre-trained model is a general-purpose language representation model, we can adapt the architecture to perform specific downstream tasks—such as classification and question answering—by attaching appropriate heads to the neural network. In our use case, the downstream task we are interested in is sequence classification. Without modifying the existing architecture, we decide to fine-tune three separate pre-trained models for each of our required categories. With the SageMaker Hugging Face Deep Learning Containers (DLCs), starting and managing NLP experiments are made simple with Hugging Face containers and the SageMaker Experiments API.
The following is a code snippet of train.py:
The following code is the Hugging Face estimator:
To validate the fine-tuned models, we use the F1-score due to the imbalanced nature of our email dataset, but also to compute other metrics such as accuracy, precision, and recall. For the SageMaker Experiments API to register the training job’s metrics, we need to first log the metrics to the training job local console, which are picked up by Amazon CloudWatch. Then we define the correct regex format to capture the CloudWatch logs. The metric definitions include the name of the metrics and regex validation for extracting the metrics from the training job:
As part of the training iteration for the classifier model, we use a confusion matrix and classification report to evaluate the result. The following figure shows the confusion matrix for line of business prediction.
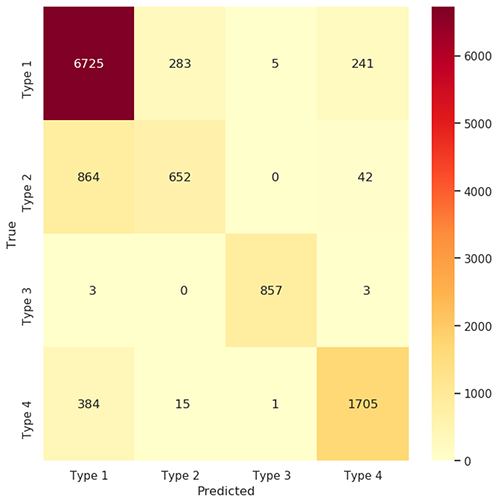
Confusion Matrix
The following screenshot shows an example of the classification report for line of business prediction.
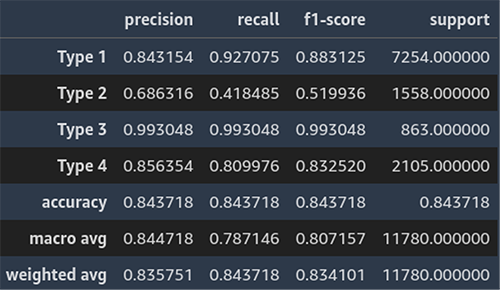
Classification Report
As a next iteration of our experiment, we’ll take advantage of multi-task learning to improve our model. Multi-task learning is a form of training where a model learns to solve multiple tasks simultaneously, because the shared information among tasks can improve learning efficiencies. By attaching two more classification heads to the original distilbert architecture, we can carry out multi-task fine-tuning, which attains reasonable metrics for our client service team.
Model deployment
In our use case, the email classifier is to be deployed to an endpoint, to which our CRM pipeline can send a batch of unclassified emails and get back predictions. Because we have other logics—such as input data cleaning and multi-task predictions—in addition to Hugging Face model inference, we need to write a custom inference script that adheres to the SageMaker standard.
The following is a code snippet of inference.py:
When everything is up and ready, we use SageMaker Pipelines to manage our training pipeline and attach it to our infrastructure to complete our MLOps setup.
To monitor the performance of the deployed model, we build a feedback loop to enable CRM to provide us with the status of classified emails when cases are closed. Based on this information, we make adjustments to improve the deployed model.
Conclusion
In this post, we shared how SageMaker facilitates the data science team at Scalable to manage the lifecycle of a data science project efficiently, namely the email classifier project. The lifecycle starts with the initial phase of data analysis and exploration with SageMaker Studio; moves on to model experimentation and deployment with SageMaker training, inference, and Hugging Face DLCs; and completes with a training pipeline with SageMaker Pipelines integrated with other AWS services. Thanks to this infrastructure, we are able to iterate and deploy new models more efficiently, and are therefore able to improve existing processes within Scalable as well as our clients’ experiences.
To learn more about Hugging Face and SageMaker, refer to the following resources:
- Use Hugging Face with Amazon SageMaker
- What are AWS Deep Learning Containers?
- Use Version 2.x of the SageMaker Python SDK: Frameworks: Hugging Face
About the Authors
 Dr. Sandra Schmid is Head of Data Analytics at Scalable GmbH. She is responsible for data-driven approaches and use cases in the company together with her teams. Her key focus is finding the best combination of machine learning and data science models and business goals in order to gain as much business value and efficiencies out of data as possible.
Dr. Sandra Schmid is Head of Data Analytics at Scalable GmbH. She is responsible for data-driven approaches and use cases in the company together with her teams. Her key focus is finding the best combination of machine learning and data science models and business goals in order to gain as much business value and efficiencies out of data as possible.
 Huy Dang Data Scientist at Scalable GmbH. His responsibilities include data analytics, building and deploying machine learning models, as well as developing and maintaining infrastructure for the data science team. In his spare time, he enjoys reading, hiking, rock climbing, and staying up to date with the latest machine learning developments.
Huy Dang Data Scientist at Scalable GmbH. His responsibilities include data analytics, building and deploying machine learning models, as well as developing and maintaining infrastructure for the data science team. In his spare time, he enjoys reading, hiking, rock climbing, and staying up to date with the latest machine learning developments.
 Mia Chang is a ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys yoga, board games, and brewing coffee.
Mia Chang is a ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys yoga, board games, and brewing coffee.
 Moritz Guertler is an Account Executive in the Digital Native Businesses segment at AWS. He focuses on customers in the FinTech space and supports them in accelerating innovation through secure and scalable cloud infrastructure.
Moritz Guertler is an Account Executive in the Digital Native Businesses segment at AWS. He focuses on customers in the FinTech space and supports them in accelerating innovation through secure and scalable cloud infrastructure.