
This is a guest post co-written with Antony Vance from Intel.
Customers are always looking for ways to improve the performance and response times of their machine learning (ML) inference workloads without increasing the cost per transaction and without sacrificing the accuracy of the results. Running ML workloads on Amazon SageMaker running Amazon Elastic Compute Cloud (Amazon EC2) C6i instances with Intel’s INT8 inference deployment can help boost the overall performance by up to four times per dollar spent while keeping the loss in inference accuracy less than 1% as compared to FP32 when applied to certain ML workloads. When it comes to running the models in embedded devices where form factor and size of the model is important, quantization can help.
Quantization is a technique to reduce the computational and memory costs of running inference by representing the weights and activations with low-precision data types like 8-bit integer (INT8) instead of the usual 32-bit floating point (FP32). In the following example figure, we show INT8 inference performance in C6i for a BERT-base model.

The BERT-base was fine-tuned with SQuAD v1.1, with PyTorch (v1.11) being the ML framework used with Intel® Extension for PyTorch. A batch size of 1 was used for the comparison. Higher batch sizes will provide different cost per 1 million inferences.
In this post, we show you how to build and deploy INT8 inference with your own processing container for PyTorch. We use Intel extensions for PyTorch for an effective INT8 deployment workflow.
Overview of the technology
EC2 C6i instances are powered by third-generation Intel Xeon Scalable processors (also called Ice Lake) with an all-core turbo frequency of 3.5 GHz.
In the context of deep learning, the predominant numerical format used for research and deployment has so far been 32-bit floating point, or FP32. However, the need for reduced bandwidth and compute requirements of deep learning models has driven research into using lower-precision numerical formats. It has been demonstrated that weights and activations can be represented using 8-bit integers (or INT8) without incurring significant loss in accuracy.
EC2 C6i instances offer many new capabilities that result in performance improvements for AI and ML workloads. C6i instances provide performance advantages in FP32 and INT8 model deployments. FP32 inference is enabled with AVX-512 improvements, and INT8 inference is enabled by AVX-512 VNNI instructions.
C6i is now available on SageMaker endpoints, and developers should expect it to provide over two times price-performance improvements for INT8 inference over FP32 inference and up to four times performance improvement when compared with C5 instance FP32 inference. Refer to the appendix for instance details and benchmark data.
Deep learning deployment on the edge for real-time inference is key to many application areas. It significantly reduces the cost of communicating with the cloud in terms of network bandwidth, network latency, and power consumption. However, edge devices have limited memory, computing resources, and power. This means that a deep learning network must be optimized for embedded deployment. INT8 quantization has become a popular approach for such optimizations for ML frameworks like TensorFlow and PyTorch. SageMaker provides you with a bring your own container (BYOC) approach and integrated tools so that you can run quantization.
For more information, refer to Lower Numerical Precision Deep Learning Inference and Training.
Solution overview
The steps to implement the solution are as follows:
- Provision an EC2 C6i instance to quantize and create the ML model.
- Use the supplied Python scripts for quantization.
- Create a Docker image to deploy the model in SageMaker using the BYOC approach.
- Use an Amazon Simple Storage Service (Amazon S3) bucket to copy the model and code for SageMaker access.
- Use Amazon Elastic Container Registry (Amazon ECR) to host the Docker image.
- Use the AWS Command Line Interface (AWS CLI) to create an inference endpoint in SageMaker.
- Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions.
This inference deployment setup uses a BERT-base model from the Hugging Face transformers repository (csarron/bert-base-uncased-squad-v1).
Prerequisites
The following are prerequisites for creating the deployment setup:
- A Linux shell terminal with the AWS CLI installed
- An AWS account with access to EC2 instance creation (C6i instance type)
- SageMaker access to deploy a SageMaker model, endpoint configuration, endpoint
- AWS Identity and Access Management (IAM) access to configure an IAM role and policy
- Access to Amazon ECR
- SageMaker access to create a notebook with instructions to launch an endpoint
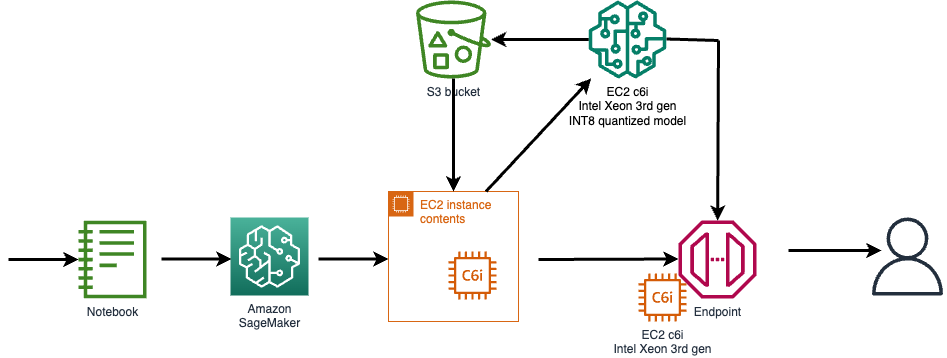
Generate and deploy a quantized INT8 model on SageMaker
Open an EC2 instance for creating your quantized model and push the model artifacts to Amazon S3. For endpoint deployment, create a custom container with PyTorch and Intel® Extension for PyTorch to deploy the optimized INT8 model. The container gets pushed into Amazon ECR and a C6i based endpoint is created to serve FP32 and INT8 models.
The following diagram illustrates the high-level flow.
To access the code and documentation, refer to the GitHub repo.
Example use case
The Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset consisting of questions posed by crowd-workers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
The following example is a question answering algorithm using a BERT-base model. Given a document as an input, the model will answer simple questions based on the learning and contexts from the input document.
The following is an example input document:
The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometers (2,700,000 sq mi), of which 5,500,000 square kilometers (2,100,000 sq mi) are covered by the rainforest.
For the question “Which name is also used to describe the Amazon rainforest in English?” we get the answer:
For the question “How many square kilometers of rainforest is covered in the basin?” we get the answer:
Quantizing the model in PyTorch
This section gives a quick overview of model quantization steps with PyTorch and Intel extensions.
The code snippets are derived from a SageMaker example.
Let’s go over the changes in detail for the function IPEX_quantize in the file quantize.py.
- Import intel extensions for PyTorch to help with quantization and optimization and import torch for array manipulations:
- Apply model calibration for 100 iterations. In this case, you are calibrating the model with the SQuAD dataset:
- Prepare sample inputs:
- Convert the model to an INT8 model using the following configuration:
- Run two iterations of forward pass to enable fusions:
- As a last step, save the TorchScript model:
Clean up
Refer to the Github repo for steps to clean up the AWS resources created.
Conclusion
New EC2 C6i instances in an SageMaker endpoint can accelerate the inference deployment up to 2.5 times greater with INT8 quantization. Quantizing the model in PyTorch is possible with a few APIs from Intel PyTorch extensions. It’s recommended to quantize the model in C6i instances so that model accuracy is maintained in endpoint deployment. The SageMaker examples GitHub repo now provides an end-to-end deployment example pipeline for quantizing and hosting INT8 models.
We encourage you to create a new model or migrate an existing model using INT8 quantization using the EC2 C6i instance type and see the performance gains for yourself.
Notice and disclaimers
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document, with the sole exception that code included in this document is licensed subject to the Zero-Clause BSD open source license (0BSD)
Appendix
New AWS instances in SageMaker with INT8 deployment support
The following table lists SageMaker instances with and without DL Boost support.
| Instance Name | Xeon Gen Codename | INT8 Enabled? | DL Boost Enabled? |
| ml.c5. xlarge – ml.c5.9xlarge | Skylake/1st | Yes | No |
| ml.c5.18xlarge | Skylake/1st | Yes | No |
| ml.c6i.1x – 32xlarge | Ice Lake/3rd | Yes | Yes |
To summarize, INT8 enabled supports the INT8 data type and computation; DL Boost enabled supports Deep Learning Boost.
Benchmark data
The following table compares the cost and relative performance between c5 and c6 instances.
Latency and throughput measured with 10000 Inference queries to Sage maker endpoints.
| E2E Latency of Inference Endpoint and Cost analysis | |||||
| P50(ms) | P90(ms) | Queries/Sec | $/1M Queries | Relative $/Performance | |
| C5.2xLarge-FP32 | 76.6 | 125.3 | 11.5 | $10.2 | 1.0x |
| c6i.2xLarge-FP32 | 70 | 110.8 | 13 | $9.0 | 1.1x |
| c6i.2xLarge-INT8 | 35.7 | 48.9 | 25.56 | $4.5 | 2.3x |
INT8 models are expected to provide 2–4 times practical performance improvements with less than 1% accuracy loss for most of the models. Above table covers overhead latency (NW and demo application)
Accuracy for BERT-base model
The following table summarizes the accuracy for the INT8 model with the SQUaD v1.1 dataset.
| Metric | FP32 | INT8 |
| Exact Match | 85.8751 | 85.5061 |
| F1 | 92.0807 | 91.8728 |
The GitHub repo comes with the scripts to check the accuracy of the SQuAD dataset. Refer to invoke-INT8.py and invoke-FP32.py scripts for testing.
Intel Extension for PyTorch
Intel® Extension for PyTorch* (an open–source project at GitHub) extends PyTorch with optimizations for extra performance boosts on Intel hardware. Most of the optimizations will be included in stock PyTorch releases eventually, and the intention of the extension is to deliver up-to-date features and optimizations for PyTorch on Intel hardware. Examples include AVX-512 Vector Neural Network Instructions (AVX512 VNNI) and Intel® Advanced Matrix Extensions (Intel® AMX).
The following figure illustrates the Intel Extension for PyTorch architecture.

For more detailed user guidance (features, performance tuning, and more) for Intel® Extension for PyTorch, refer to Intel® Extension for PyTorch* user guidance.
About the Authors
 Rohit Chowdhary is a Sr. Solutions Architect in the Strategic Accounts team at AWS.
Rohit Chowdhary is a Sr. Solutions Architect in the Strategic Accounts team at AWS.
 Aniruddha Kappagantu is a Software Development Engineer in the AI Platforms team at AWS.
Aniruddha Kappagantu is a Software Development Engineer in the AI Platforms team at AWS.
 Antony Vance is an AI Architect at Intel with 19 years of experience in computer vision, machine learning, deep learning, embedded software, GPU, and FPGA.
Antony Vance is an AI Architect at Intel with 19 years of experience in computer vision, machine learning, deep learning, embedded software, GPU, and FPGA.