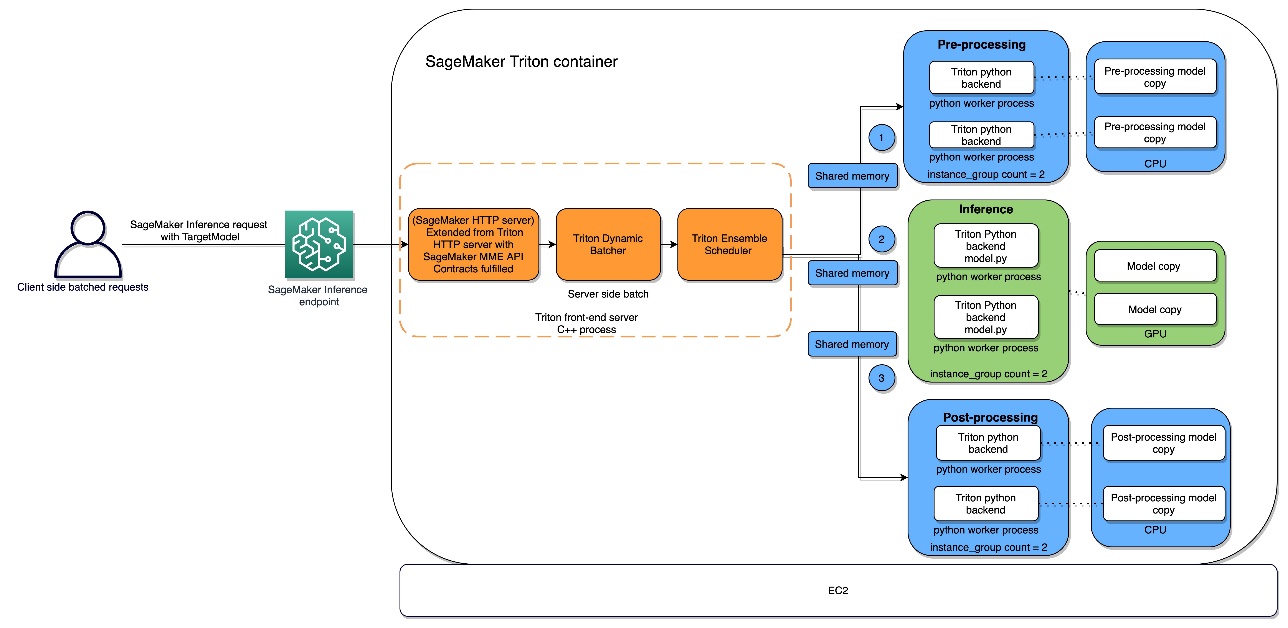
Optimize AWS Inferentia utilization with FastAPI and PyTorch models on Amazon EC2 Inf1 & Inf2 instances
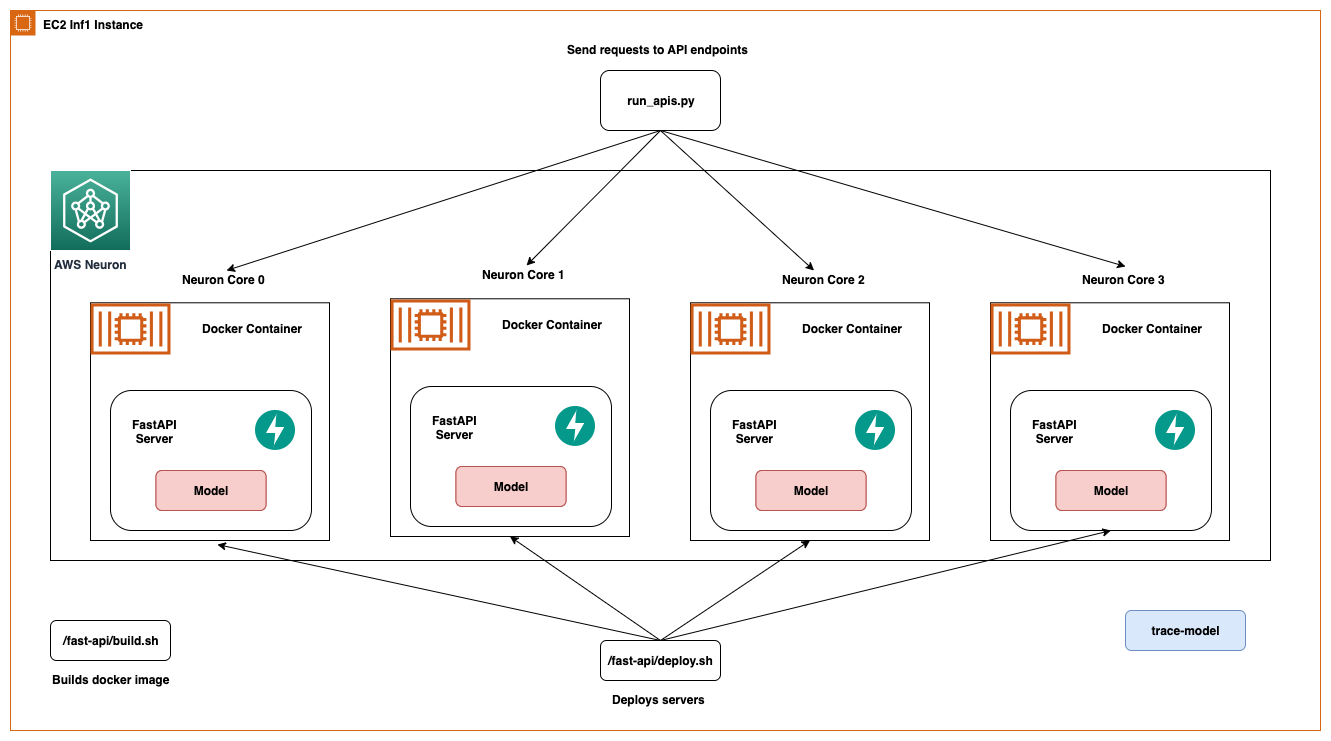
When deploying Deep Learning models at scale, it is crucial to effectively utilize the underlying hardware to maximize performance and cost benefits. For production workloads requiring high throughput and low latency, the selection of the Amazon Elastic Compute Cloud (EC2) …